w ostatnich latach zwiększenie algorytmów zyskało ogromną popularność w zawodach z zakresu data science lub machine learning. Większość zwycięzców tych konkursów wykorzystuje algorytmy wzmacniające, aby osiągnąć wysoką dokładność. Konkursy te stanowią globalną platformę do nauki, odkrywania i dostarczania rozwiązań dla różnych problemów biznesowych i rządowych. Algorytmy Boosting łączą wiele modeli o niskiej dokładności (lub słabych) w celu stworzenia modeli o wysokiej dokładności(lub silnych). Może być wykorzystywany w różnych dziedzinach, takich jak kredyty, ubezpieczenia, marketing i sprzedaż. Algorytmy wspomagające, takie jak AdaBoost, Gradient Boosting i XGBoost, są powszechnie stosowanymi algorytmami uczenia maszynowego, aby wygrywać konkursy z zakresu nauk o danych. W tym samouczku poznasz algorytm wspomagania adaboost ensemble, a omówione zostaną następujące tematy:
- Ensemble Machine Learning Approach
- Bagging
- Boosting
- stacking
- klasyfikator AdaBoost
- jak działa algorytm AdaBoost?
- budowanie modelu w Pythonie
- plusy i minusy
- podsumowanie
Ensemble Machine Learning Approach
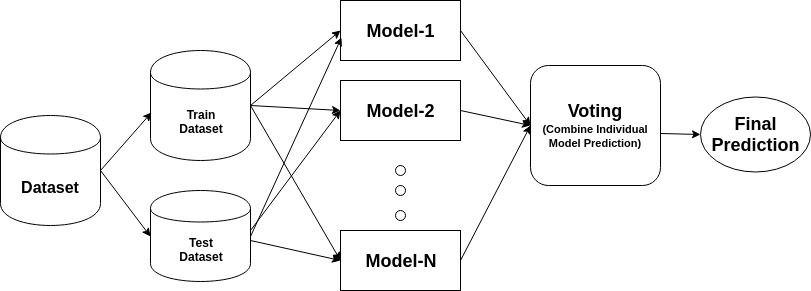
ensemble jest modelem złożonym, łączącym w sobie serię mało wydajnych klasyfikatorów w celu stworzenia ulepszonego klasyfikatora. Tutaj powróciły Indywidualne głosowanie klasyfikatora i ostateczna Etykieta przewidywania, która przeprowadza głosowanie większościowe. Zespoły oferują większą dokładność niż klasyfikator indywidualny lub bazowy. Metody Ensemble mogą być równoległe poprzez przydzielenie każdego podstawowego ucznia do różnych-różnych maszyn. Wreszcie, można powiedzieć, że metody Ensemble learning to meta-algorytmy, które łączą kilka metod uczenia maszynowego w jeden model predykcyjny, aby zwiększyć wydajność. Metody Ensemble mogą zmniejszać wariancję za pomocą podejścia bagging, stronniczość za pomocą podejścia boosting lub poprawiać prognozy za pomocą podejścia stacking.
-
Bagging oznacza agregację bootstrap. Łączy wielu uczniów w sposób zmniejszający zmienność szacunków. Na przykład, losowe leśne pociągi M drzewo decyzyjne, możesz trenować m różnych drzew na różnych losowych podzbiorach danych i przeprowadzać głosowanie na ostateczne przewidywanie. Metody workowania zespołów to Las losowy i dodatkowe drzewa.
-
algorytmy zwiększające są zbiorem klasyfikatora o niskiej dokładności, aby utworzyć klasyfikator o wysokiej dokładności. Klasyfikator niskiej dokładności (lub słaby klasyfikator) oferuje dokładność lepszą niż rzut monetą. Bardzo dokładny klasyfikator (lub silny klasyfikator) oferuje współczynnik błędu bliski 0. Boosting algorytm może śledzić model, który nie udało dokładne przewidywania. Algorytmy Boosting są mniej dotknięte problemem overfitting. Następujące trzy algorytmy zyskały ogromną popularność w konkursach z zakresu nauk o danych.
- AdaBoost (Adaptive Boost)
- Gradient Tree Boost
- XGBoost
-
układanie w stos (lub uogólnianie w stos) to technika uczenia się zespołu, która łączy wiele podstawowych modeli klasyfikacji prognoz w nowy zestaw danych. Te nowe dane są traktowane jako dane wejściowe dla innego klasyfikatora. Ten klasyfikator zatrudniony do rozwiązania tego problemu. Układanie jest często określane jako mieszanie.
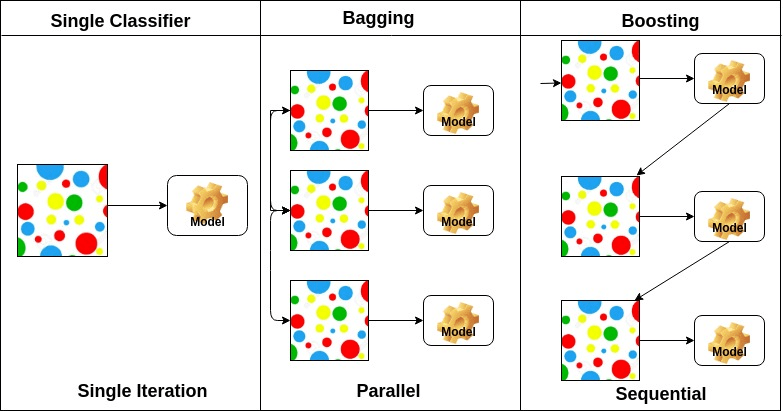
na podstawie układu podstawowych uczących się, metody ensemble można podzielić na dwie grupy: w równoległych metodach ensemble, uczący się base są generowane równolegle na przykład. Losowy Las. W metodach sequential ensemble uczniowie podstawy są generowani sekwencyjnie, na przykład AdaBoost.
ze względu na rodzaj podstawowego uczącego się, metody ensemble można podzielić na dwie grupy: homogeniczna metoda ensemble wykorzystuje ten sam typ podstawowego ucznia w każdej iteracji. metoda heterogeniczna ensemble wykorzystuje w każdej iteracji inny typ podstawowego ucznia.
Adaboost Classifier
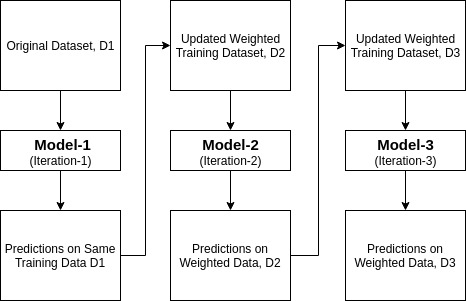
Ada-boost lub Adaptive Boosting jest jednym z ensemble boosting classifier zaproponowanym przez Yoava Freunda i Roberta Schapire ’ a w 1996 roku. Łączy wiele klasyfikatorów, aby zwiększyć dokładność klasyfikatorów. AdaBoost jest iteracyjną metodą ensemble. Adaboost classifier buduje silny klasyfikator, łącząc wiele słabo działających klasyfikatorów, dzięki czemu otrzymasz silny klasyfikator o wysokiej dokładności. Podstawową koncepcją adaboost jest ustawianie wagi klasyfikatorów i szkolenie próbki danych w każdej iteracji w taki sposób, aby zapewnić dokładne przewidywanie nietypowych obserwacji. Każdy algorytm uczenia maszynowego może być użyty jako klasyfikator bazowy, jeśli akceptuje wagi na zestawie treningowym. Adaboost powinien spełniać dwa warunki:
- klasyfikator powinien być szkolony interaktywnie na różnych przykładach ćwiczeń ważonych.
- w każdej iteracji stara się zapewnić doskonałe dopasowanie do tych przykładów, minimalizując błędy treningowe.
jak działa algorytm AdaBoost?
działa w następujących krokach:
- początkowo Adaboost wybiera losowo podzbiór treningowy.
- iteracyjnie trenuje model uczenia maszynowego AdaBoost, wybierając zestaw treningowy na podstawie dokładnego przewidywania ostatniego treningu.
- przypisuje większą wagę błędnym klasyfikowanym obserwacjom, dzięki czemu w następnej iteracji te obserwacje otrzymają wysokie prawdopodobieństwo klasyfikacji.
- ponadto przypisuje wagę szkolonemu klasyfikatorowi w każdej iteracji zgodnie z dokładnością klasyfikatora. Dokładniejszy klasyfikator uzyska wysoką wagę.
- ten proces powtarza się, aż kompletne dane treningowe pasują bez żadnego błędu lub do osiągnięcia określonej maksymalnej liczby estymatorów.
- aby sklasyfikować, wykonaj „głosowanie” we wszystkich algorytmach uczenia się, które zbudowałeś.
budowanie modelu w Pythonie
Importowanie wymaganych bibliotek
najpierw załadujmy wymagane biblioteki.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsŁadowanie zestawu danych
w modelu części budynku można użyć zestawu danych tęczówki, który jest bardzo znanym problemem klasyfikacji wielu klas. Ten zbiór danych obejmuje 4 cechy (długość sepalu, szerokość sepalu, długość płatka, szerokość płatka) i cel (rodzaj kwiatu). Dane te mają trzy rodzaje klas kwiatów: Setosa, Versicolour i Virginica. Zbiór danych jest dostępny w bibliotece scikit-learn lub można go również pobrać z biblioteki UCI Machine Learning.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetdzielenie zbioru danych
aby zrozumieć wydajność modelu, podzielenie zbioru danych na zestaw treningowy i zestaw testowy jest dobrą strategią.
Podzielmy zbiór danych za pomocą funkcji train_test_split (). musisz przekazać 3 Funkcje parametrów, cel i rozmiar test_set.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testbudowanie modelu AdaBoost
stwórzmy Model AdaBoost za pomocą Scikit-learn. AdaBoost używa Decision Tree Classifier jako domyślnego klasyfikatora.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)„najważniejsze parametry to base_estimator, n_estimator i learning_rate.”(Adaboost, Chris Albon)
- base_estimator: jest to słaby uczeń używany do trenowania modelu. Używa DecisionTreeClassifier jako domyślnego słabego ucznia do celów szkoleniowych. Można również określić różne algorytmy uczenia maszynowego.
- n_estimatory: Liczba słabych uczniów do iteracyjnego szkolenia.
- learning_rate: zwiększa wagę słabych uczniów. Używa 1 jako wartości domyślnej.
Oceń Model
oszacujmy, jak dokładnie klasyfikator lub model może przewidzieć rodzaj kultywarów.
dokładność można obliczyć, porównując rzeczywiste wartości zestawu testowego i wartości przewidywane.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888cóż, masz dokładność 88.88%, uznaną za dobrą dokładność.
w celu dalszej oceny można również utworzyć model przy użyciu różnych estymatorów bazowych.
używając różnych podstawowych uczniów
użyłem SVC jako podstawowego estymatora. Możesz użyć dowolnego ucznia ML jako podstawowego estymatora, jeśli akceptuje wagę próbki, taką jak drzewo decyzyjne, klasyfikator wektorów pomocniczych.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556masz wskaźnik klasyfikacji 95,55%, uważany za dobrą celność.
w tym przypadku Estymator bazowy SVC uzyskuje lepszą dokładność niż Estymator bazowy drzewa decyzyjnego.
plusy
AdaBoost jest łatwy do wdrożenia. Iteracyjnie koryguje błędy słabego klasyfikatora i poprawia dokładność, łącząc słabych uczniów. Z AdaBoost możesz korzystać z wielu podstawowych klasyfikatorów. AdaBoost nie jest podatny na przepełnienie. Można to znaleźć na podstawie wyników eksperymentu,ale nie ma konkretnego powodu.
wady
AdaBoost jest wrażliwy na hałas. To jest bardzo wpływ odstających, ponieważ stara się idealnie dopasować każdy punkt. AdaBoost jest wolniejszy w porównaniu do XGBoost.
podsumowanie
Gratulacje, dotarłeś do końca tego tutoriala!
w tym samouczku nauczyłeś się podejść do uczenia maszynowego zespołu, algorytmu AdaBoost, działa, buduje modele i ocenia za pomocą pakietu python Scikit-learn. Omówiono również jego plusy i minusy.