In recent years, boosting algorithms gained massive popularity in data science or machine learning competitions. A maioria dos vencedores destas competições usam algoritmos impulsionadores para alcançar alta precisão. Estes concursos de Ciência dos dados fornecem a plataforma global para a aprendizagem, exploração e fornecimento de soluções para vários problemas de negócios e do governo. Boosting algorithms combine multiple low accuracy(or weak) models to create a high accuracy (or strong) models. Pode ser utilizado em vários domínios, como crédito, seguros, marketing e vendas. Boosting algorithms such as AdaBoost, Gradient Boost, and XGBoost are widely used machine learning algorithm to win the data science competitions. Neste tutorial, você vai aprender o adaboost de aprendizagem de máquina ensemble impulsionar o algoritmo, e os seguintes temas serão abordados:
- Ensemble de Aprendizagem de Máquina Abordagem
- Ensacamento
- Reforço
- empilhamento
- adaboost de aprendizagem de máquina do Classificador
- Como funciona o algoritmo adaboost de aprendizagem de máquina de trabalho?
- Modelo de Prédio em Python
- Prós e contras
- Conclusão
Ensemble Máquina Abordagem de Aprendizagem
Um grupo é um modelo composto, que combina uma série de baixo desempenho classificadores, com o objectivo de criar uma melhor classificador. Aqui, voto individual classificador e rótulo de previsão final retornaram que realiza votação por maioria. Os conjuntos oferecem mais precisão do que o classificador individual ou de base. Os métodos conjuntos podem paralelizar-se atribuindo cada aluno de base a máquinas diferentes. Finalmente, você pode dizer Métodos de aprendizagem Ensemble são meta-algoritmos que combinam vários métodos de aprendizagem de máquina em um único modelo preditivo para aumentar o desempenho. Métodos conjuntos podem diminuir a variância usando abordagem de ensacamento, viés usando uma abordagem de reforço, ou melhorar as previsões usando abordagem de empilhamento.
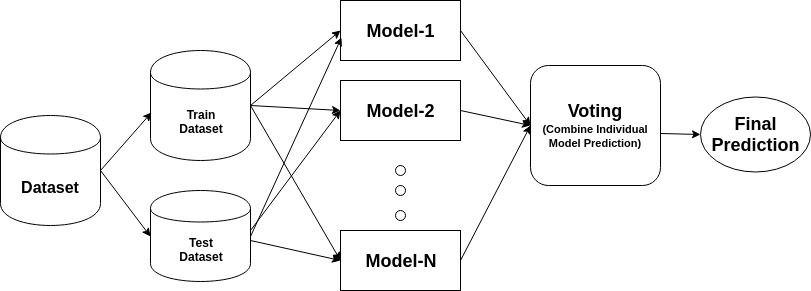
-
Bagging significa agregação bootstrap. Combina múltiplos alunos de forma a reduzir a variância das estimativas. Por exemplo, o random forest trens m Decision Tree, você pode treinar m árvores diferentes em diferentes subconjuntos aleatórios dos dados e realizar votação para a previsão final. Os métodos de ensemblagem são Floresta aleatória e árvores Extras.
-
Boosting algorithms é um conjunto do classificador de baixa precisão para criar um classificador de alta precisão. Classifier de baixa precisão (ou classifier fraco) oferece a precisão melhor do que o flipping de uma moeda. Classifier altamente preciso (ou classificador forte) oferecer taxa de erro perto de 0. O algoritmo impulsionador pode rastrear o modelo que falhou na previsão precisa. Os algoritmos impulsionadores são menos afetados pelo problema de sobrecarga. Os três algoritmos seguintes ganharam enorme popularidade em competições de ciência dos dados.
- adaboost de aprendizagem de máquina (Adaptive Boosting)
- Gradiente Árvore de Impulsionar
- XGBoost
-
Empilhamento(ou empilhados generalização) é um conjunto de técnicas de aprendizagem que combina vários da base de dados de modelos de classificação previsões em um novo conjunto de dados. Estes novos dados são tratados como os dados de entrada para outro classificador. Este classificador empregou para resolver este problema. Empilhamento é muitas vezes referido como Mistura.
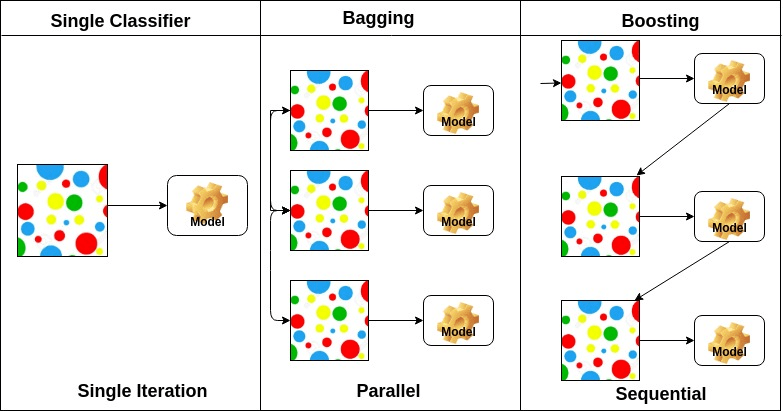
com base no arranjo de aprendizes de base, métodos conjuntos podem ser divididos em dois grupos: em métodos conjuntos paralelos, aprendizes de base são gerados em paralelo, por exemplo. Floresta Aleatória. In sequential ensemble methods, base learners are generated sequentially for example AdaBoost.
com base no tipo de aprendizes de base, os métodos conjuntos podem ser divididos em dois grupos: o método do conjunto homogêneo usa o mesmo tipo de aluno base em cada iteração. o método do conjunto heterogêneo usa o diferente tipo de aprendiz de base em cada iteração.
AdaBoost Classifier
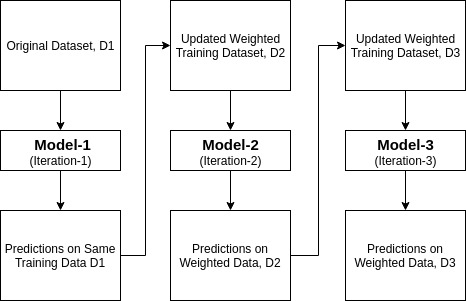
ada-boost ou Adaptive Boosting é um dos classificados de conjunto boost proposto por Yoav Freund e Robert Schapire em 1996. Ele combina vários classificadores para aumentar a precisão dos Classificadores. AdaBoost é um método iterativo ensemble. O classificador AdaBoost constrói um classificador forte, combinando vários classificadores de desempenho deficiente para que você obtenha um classificador forte de alta precisão. O conceito básico por trás do Adaboost é definir os pesos dos classificadores e treinar a amostra de dados em cada iteração, de modo a garantir as previsões precisas de observações incomuns. Qualquer algoritmo de aprendizado de máquina pode ser usado como classificador de base se aceitar pesos no conjunto de treinamento. Adaboost deve preencher duas condições:
- o classificador deve ser treinado interactivamente em vários exemplos de treino pesados.
- em cada iteração, ele tenta fornecer um excelente ajuste para estes exemplos, minimizando o erro de treinamento.
como funciona o algoritmo AdaBoost?
funciona nas seguintes etapas:
- inicialmente, Adaboost seleciona um subconjunto de treinamento aleatoriamente.
- it it it itteratively trains the AdaBoost machine learning model by selecting the training set based on the accurate prediction of the last training.
- atribui o maior peso a observações classificadas erradas de modo que na próxima iteração estas observações terão a alta probabilidade de classificação.
- também, atribui o peso ao classificador treinado em cada iteração de acordo com a precisão do Classificador. O classificador mais preciso terá um peso elevado.
- este processo iterate até que os dados completos de formação se encaixem sem qualquer erro ou até que seja atingido o número máximo especificado de estimadores.
- para classificar, realizar um “voto” em todos os algoritmos de aprendizagem que construiu.
modelo de construção em Python
importando bibliotecas necessárias
vamos primeiro carregar as bibliotecas necessárias.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsconjunto de Dados De Carregamento
no modelo da parte do edifício, pode utilizar o conjunto de dados IRIS, que é um famoso problema de classificação multi-classes. Este conjunto de dados compreende 4 Características (Comprimento do sepal, largura do sepal, comprimento da pétala, largura da pétala) e um alvo (o tipo de flor). Estes dados têm três tipos de classes de flores: Setosa, versicolor e Virginica. O conjunto de dados está disponível na biblioteca scikit-learn, ou você também pode baixá-lo a partir da biblioteca UCI Machine Learning.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit dataset
para compreender o desempenho do modelo, dividir o conjunto de dados em um conjunto de treinamento e um conjunto de testes é uma boa estratégia.
vamos dividir o conjunto de dados usando a função train_test_split(). você precisa passar 3 características de parâmetros, alvo, e tamanho test_ set.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testconstruir o modelo AdaBoost
vamos criar o modelo AdaBoost usando Scikit-learn. O AdaBoost usa o classificador da árvore de decisão como classificador predefinido.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“Os parâmetros mais importantes são base_estimator, n_estimators, e learning_rate.”(AdaBoost Classifier, Chris Albon)
- base_estimator: é um aluno fraco usado para treinar o modelo. Utiliza a Decisãoreclassificadora como aprendiz fraco por defeito para fins de formação. Você também pode especificar diferentes algoritmos de aprendizado de máquina.
- n_estimators: Number of weak learners to train iteratively.
- taxa de aprendizagem: contribui para os pesos dos alunos fracos. Ele usa 1 como um valor padrão.
avaliar o modelo
vamos estimar, com que precisão o classificador ou modelo pode prever o tipo de cultivares.Pode calcular-se a precisão
comparando os valores reais dos conjuntos de ensaio e os valores previstos.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888bem, tens uma precisão de 88,88%, considerada uma boa precisão.
para uma avaliação mais aprofundada, você também pode criar um modelo usando diferentes estimadores de Base.
utilizando diferentes alunos de Base
usei a VPC como estimador de base. Você pode usar qualquer ml learner como estimador de base se ele aceitar o peso da amostra, como Árvore de decisão, suporte classificador de vetor.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556bem, você tem uma taxa de classificação de 95,55%, considerado como boa precisão.
neste caso, o estimador de base VPC está obtendo melhor precisão do que o estimador de base de decisão.
Pros
AdaBoost é fácil de implementar. Iterativamente corrige os erros do Classificador fraco e melhora a precisão combinando alunos fracos. Você pode usar muitos classificadores de base com AdaBoost. O AdaBoost não é propenso a exagerar. Isto pode ser descoberto através de resultados de experimentos, mas não há nenhuma razão concreta disponível.
Cons
AdaBoost é sensível aos dados sobre ruído. É altamente afetado por anómalos, porque tenta encaixar cada ponto perfeitamente. O AdaBoost é mais lento em comparação com o XGBoost.
conclusão
Parabéns, você chegou ao fim deste tutorial!
neste tutorial, você aprendeu o Ensemble Machine Learning Approaches, o algoritmo AdaBoost, está funcionando, model building e avaliação usando Python Scikit-learn package. Além disso, discutiu seus prós e contras.