în ultimii ani, creșterea algoritmilor a câștigat o popularitate masivă în știința datelor sau în competițiile de învățare automată. Majoritatea câștigătorilor acestor competiții folosesc algoritmi de stimulare pentru a obține o precizie ridicată. Aceste competiții de știință a datelor oferă platforma globală pentru învățarea, explorarea și furnizarea de soluții pentru diverse probleme de afaceri și guvernamentale. Algoritmii de stimulare combină mai multe modele de precizie redusă(sau slabe) pentru a crea modele de înaltă precizie(sau puternice). Poate fi utilizat în diverse domenii, cum ar fi creditul, asigurările, marketingul și vânzările. Algoritmi de stimulare, cum ar fi AdaBoost, Gradient Boosting și XGBoost, sunt utilizați pe scară largă algoritm de învățare automată pentru a câștiga competițiile de știință a datelor. În acest tutorial, veți învăța algoritmul de stimulare a ansamblului AdaBoost, iar următoarele subiecte vor fi acoperite:
- ansamblu abordare de învățare mașină
- insacuire
- stimularea
- stivuire
- clasificator AdaBoost
- cum funcționează algoritmul AdaBoost?
- model de construcție în Python
- Pro și contra
- concluzie
abordare de învățare automată a ansamblului
un ansamblu este un model compozit, combină o serie de clasificatori cu performanțe scăzute cu scopul de a crea un clasificator îmbunătățit. Aici, votul clasificator individual și eticheta finală de predicție au revenit care efectuează votul majoritar. Ansamblurile oferă mai multă precizie decât clasificatorul individual sau de bază. Metodele de ansamblu pot paraleliza prin alocarea fiecărui cursant de bază unor mașini diferite. În cele din urmă, puteți spune că metodele de învățare a ansamblului sunt meta-algoritmi care combină mai multe metode de învățare automată într-un singur model predictiv pentru a crește performanța. Metodele de ansamblu pot reduce varianța folosind abordarea de ambalare, părtinirea folosind o abordare de stimulare sau îmbunătățirea predicțiilor folosind abordarea de stivuire.
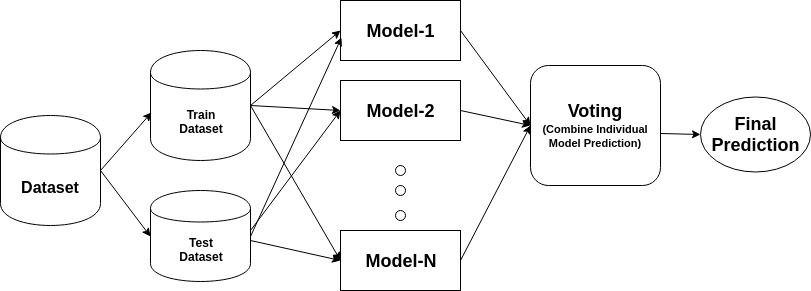
-
insacuire standuri pentru Bootstrap agregare. Acesta combină mai mulți cursanți într-un mod de a reduce variația estimărilor. De exemplu, pădure aleatoare trenuri m decizie copac, puteți instrui m copaci diferite pe diferite subseturi aleatoare ale datelor și de a efectua vot pentru predicție finală. Insacuire ansambluri metode sunt pădure aleatoare și copaci suplimentare.
-
algoritmii de stimulare sunt un set de clasificator cu precizie redusă pentru a crea un clasificator extrem de precis. Clasificatorul de precizie scăzută (sau clasificatorul slab) oferă precizia mai bună decât răsturnarea unei monede. Clasificator foarte precis (sau clasificator puternic) oferă o rată de eroare apropiată de 0. Stimularea algoritm poate urmări modelul care nu a reușit predicția exactă. Algoritmii de stimulare sunt mai puțin afectați de problema suprasolicitării. Următorii trei algoritmi au câștigat o popularitate masivă în competițiile de știință a datelor.
- AdaBoost (creșterea adaptivă)
- creșterea gradientului arborelui
- XGBoost
-
stivuirea (sau generalizarea stivuită) este o tehnică de învățare a ansamblului care combină mai multe predicții ale modelelor de clasificare de bază într-un nou set de date. Aceste date noi sunt tratate ca date de intrare pentru un alt clasificator. Acest clasificator folosit pentru a rezolva această problemă. Stivuirea este adesea denumită amestecare.
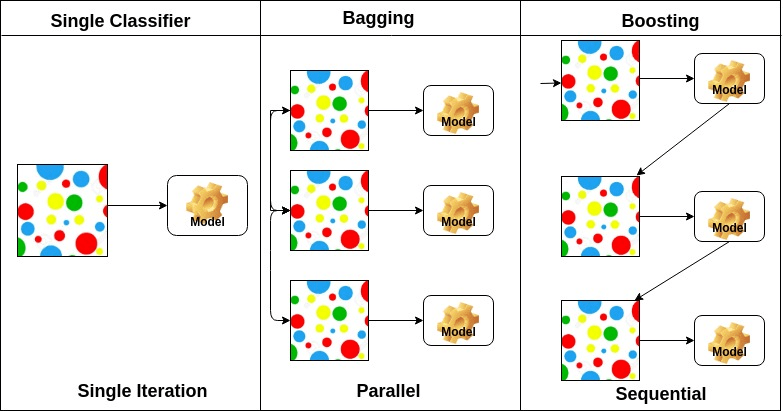
pe baza aranjamentului cursanților de bază, metodele de ansamblu pot fi împărțite în două grupe: în metodele de ansamblu paralele, cursanții de bază sunt generați în paralel, de exemplu. Pădure Aleatoare. În metodele ansamblului secvențial, cursanții de bază sunt generați secvențial, de exemplu AdaBoost.
pe baza tipului de cursanți de bază, metodele de ansamblu pot fi împărțite în două grupe: metoda ansamblului omogen folosește același tip de cursant de bază în fiecare iterație. metoda ansamblului eterogen utilizează tipul diferit de cursant de bază în fiecare iterație.
AdaBoost clasificator
Ada-boost sau stimularea adaptivă este unul dintre ansamblu stimularea clasificator propus de Yoav Freund și Robert Schapire în 1996. Acesta combină mai mulți clasificatori pentru a crește precizia clasificatorilor. AdaBoost este o metodă de ansamblu iterativ. AdaBoost clasificator construiește un clasificator puternic prin combinarea mai multor clasificatori slab performante, astfel încât veți obține de înaltă precizie clasificator puternic. Conceptul de bază din spatele Adaboost este de a stabili greutățile clasificatorilor și de a instrui eșantionul de date în fiecare iterație, astfel încât să asigure predicțiile exacte ale observațiilor neobișnuite. Orice algoritm de învățare automată poate fi folosit ca clasificator de bază dacă acceptă greutăți pe setul de antrenament. Adaboost ar trebui să îndeplinească două condiții:
- clasificatorul ar trebui să fie instruit interactiv pe diferite exemple de formare cântărite.
- în fiecare iterație, încearcă să ofere o potrivire excelentă pentru aceste exemple prin minimizarea erorilor de antrenament.
cum funcționează algoritmul AdaBoost?
funcționează în următorii pași:
- inițial, Adaboost selectează aleatoriu un subset de antrenament.
- antrenează iterativ modelul de învățare automată AdaBoost selectând setul de antrenament pe baza predicției exacte a ultimului antrenament.
- atribuie greutatea mai mare observațiilor clasificate greșite, astfel încât în următoarea iterație aceste observații vor obține probabilitatea mare de clasificare.
- de asemenea, atribuie greutatea Clasificatorului instruit în fiecare iterație în funcție de precizia Clasificatorului. Clasificatorul mai precis va primi o greutate mare.
- acest proces itera până când datele complete de formare se potrivește fără nici o eroare sau până când a ajuns la numărul maxim specificat de estimatori.
- pentru a clasifica, efectuați un „vot” pentru toți algoritmii de învățare pe care i-ați construit.
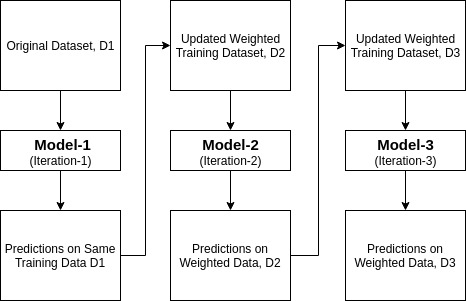
model de construcție în Python
importarea bibliotecilor necesare
să încărcăm mai întâi bibliotecile necesare.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsset de date de încărcare
în modelul partea de construcție, puteți utiliza setul de date IRIS, care este o problemă de clasificare multi-clasă foarte celebru. Acest set de date cuprinde 4 caracteristici (lungimea sepal, lățimea sepal, lungimea petală, lățimea petală) și o țintă (tipul de floare). Aceste date au trei tipuri de clase de flori: Setosa, Versicolour și Virginica. Setul de date este disponibil în biblioteca scikit-learn sau îl puteți descărca și din biblioteca UCI Machine Learning.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit set de date
pentru a înțelege performanța modelului, împărțirea setului de date într-un set de instruire și un set de testare este o strategie bună.
Să împărțim setul de date utilizând funcția train_test_split(). ai nevoie pentru a trece 3 parametri caracteristici, țintă, și dimensiunea test_set.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testconstruirea modelului AdaBoost
să creăm Modelul AdaBoost folosind Scikit-learn. AdaBoost utilizează clasificator arbore de decizie ca clasificator implicit.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)„cei mai importanți parametri sunt base_estimator, n_estimators, și learning_rate.”(Clasificator Adaboost, Chris Albon)
- base_estimator: este un cursant slab folosit pentru a instrui modelul. Acesta utilizează DecisionTreeClassifier ca cursant slab implicit în scop de formare. De asemenea, puteți specifica diferiți algoritmi de învățare automată.
- n_estimators: Numărul de elevi slabi pentru a instrui iterativ.
- learning_rate: contribuie la greutățile elevilor slabi. Folosește 1 ca valoare implicită.
evaluați Modelul
să estimăm cât de precis clasificatorul sau modelul poate prezice tipul de soiuri.
precizia poate fi calculată prin compararea valorilor reale stabilite de test și a valorilor prezise.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Ei bine, ai o precizie de 88,88%, considerată o precizie bună.
pentru o evaluare suplimentară, puteți crea, de asemenea, un model folosind diferite estimatori de bază.
folosind diferiți cursanți de bază
am folosit SVC ca estimator de bază. Puteți utiliza orice cursant ML ca estimator de bază dacă acceptă greutatea eșantionului, cum ar fi arborele de decizie, clasificatorul de vectori de sprijin.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Ei bine, ai o rată de clasificare de 95.55%, considerat ca o precizie bună.
în acest caz, Estimatorul de bază SVC obține o precizie mai bună decât Estimatorul de bază al arborelui de decizie.
Pro
AdaBoost este ușor de implementat. Corectează iterativ greșelile Clasificatorului slab și îmbunătățește precizia prin combinarea cursanților slabi. Puteți utiliza mai multe Clasificatoare de bază cu AdaBoost. AdaBoost nu este predispus la suprasolicitare. Acest lucru poate fi aflat prin rezultatele experimentului, dar nu există niciun motiv concret disponibil.
contra
AdaBoost este sensibil la datele de zgomot. Este foarte afectat de valori aberante, deoarece încearcă să se potrivească perfect fiecărui punct. AdaBoost este mai lent în comparație cu XGBoost.
concluzie
Felicitări, ați ajuns la sfârșitul acestui tutorial!
în acest tutorial, ați învățat abordările ansamblului de învățare automată, algoritmul AdaBoost, funcționează, construirea modelului și evaluarea folosind Pachetul Python Scikit-learn. De asemenea, a discutat argumentele sale pro și contra.