In den letzten Jahren haben Boosting-Algorithmen bei Data-Science- oder Machine-Learning-Wettbewerben massive Popularität erlangt. Die meisten Gewinner dieser Wettbewerbe verwenden Boosting-Algorithmen, um eine hohe Genauigkeit zu erreichen. Diese Data Science-Wettbewerbe bieten die globale Plattform zum Lernen, Erforschen und Bereitstellen von Lösungen für verschiedene Geschäfts- und Regierungsprobleme. Boosting-Algorithmen kombinieren mehrere Modelle mit geringer Genauigkeit (oder schwach), um Modelle mit hoher Genauigkeit (oder stark) zu erstellen. Es kann in verschiedenen Bereichen wie Kredit, Versicherung, Marketing und Vertrieb eingesetzt werden. Boosting-Algorithmen wie AdaBoost, Gradient Boosting und XGBoost sind weit verbreitete Algorithmen für maschinelles Lernen, um die Data Science-Wettbewerbe zu gewinnen. In diesem Tutorial lernen Sie den AdaBoost Ensemble Boosting-Algorithmus kennen und die folgenden Themen werden behandelt:
- Ensemble-Ansatz für maschinelles Lernen
- Absacken
- Boosten
- Stapeln
- AdaBoost-Klassifikator
- Wie funktioniert der AdaBoost-Algorithmus?
- Gebäudemodell in Python
- Vor- und Nachteile
- Fazit
Ensemble-Ansatz für maschinelles Lernen
Ein Ensemble ist ein zusammengesetztes Modell, das eine Reihe von Klassifikatoren mit geringer Leistung kombiniert, um einen verbesserten Klassifikator zu erstellen. Hier individuelle Klassifikator Abstimmung und endgültige Vorhersage Label zurückgegeben, die Mehrheitswahl führt. Ensembles bieten mehr Genauigkeit als Einzel- oder Basisklassifikatoren. Ensemble-Methoden können parallelisiert werden, indem jeder Basis-Lerner verschiedenen Maschinen zugewiesen wird. Schließlich kann man sagen, dass Ensemble-Lernmethoden Metaalgorithmen sind, die mehrere Methoden des maschinellen Lernens in einem einzigen Vorhersagemodell kombinieren, um die Leistung zu steigern. Ensemble-Methoden können die Varianz mithilfe des Bagging-Ansatzes verringern, die Verzerrung mithilfe eines Boosting-Ansatzes verringern oder die Vorhersagen mithilfe des Stacking-Ansatzes verbessern.
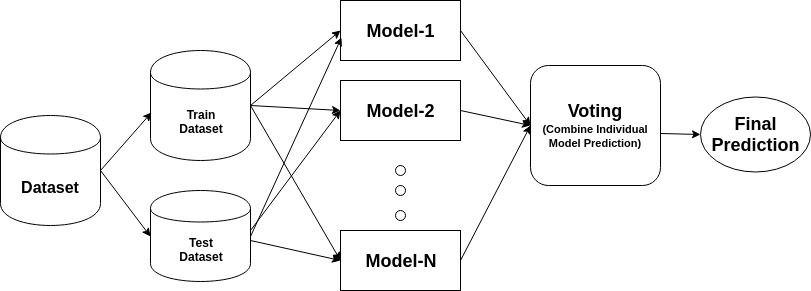
-
Bagging steht für Bootstrap Aggregation. Es kombiniert mehrere Lernende in einer Weise, die Varianz der Schätzungen zu reduzieren. Sie können M verschiedene Bäume für verschiedene zufällige Teilmengen der Daten trainieren und eine Abstimmung für die endgültige Vorhersage durchführen. Bagging-Methoden sind Random Forest und Extra Trees.
-
Boosting-Algorithmen sind ein Satz des niedriggenauen Klassifikators, um einen hochgenauen Klassifikator zu erstellen. Low Accuracy Classifier (oder Weak Classifier) bietet die Genauigkeit besser als das Werfen einer Münze. Hochgenaue Klassifikatoren ( oder starke Klassifikatoren) bieten eine Fehlerrate nahe 0. Der Algorithmus kann das Modell verfolgen, bei dem die genaue Vorhersage fehlgeschlagen ist. Boosting-Algorithmen sind weniger vom Problem der Überanpassung betroffen. Die folgenden drei Algorithmen haben bei Data-Science-Wettbewerben enorme Popularität erlangt.
- AdaBoost (Adaptives Boosting)
- Gradient Tree Boosting
- XGBoost
-
Stacking (oder gestapelte Verallgemeinerung) ist eine Ensemble-Lerntechnik, die Vorhersagen mehrerer Basisklassifizierungsmodelle zu einem neuen Datensatz kombiniert. Diese neuen Daten werden als Eingabedaten für einen anderen Klassifikator behandelt. Dieser Klassifikator verwendet, um dieses Problem zu lösen. Das Stapeln wird oft als Mischen bezeichnet.
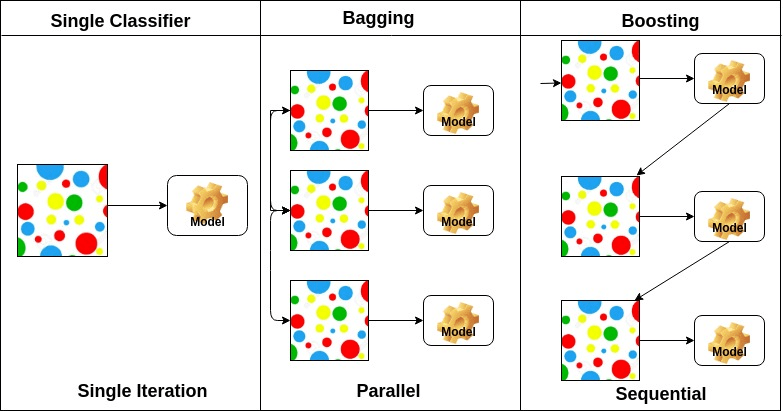
Anhand der Anordnung der Basis-Lerner lassen sich Ensemble-Methoden in zwei Gruppen einteilen: Bei parallelen Ensemble-Methoden werden beispielsweise Basis-Lerner parallel generiert. Zufälliger Wald. Bei sequentiellen Ensemble-Verfahren werden Basis-Lerner sequentiell generiert, z.B. AdaBoost.
Auf der grundlage der art der basis lernenden, ensemble methoden können unterteilt werden in zwei gruppen: die homogene Ensemble-Methode verwendet in jeder Iteration den gleichen Typ von Basis-Lerner. die heterogene Ensemble-Methode verwendet in jeder Iteration den unterschiedlichen Typ des Basis-Lernenden.
AdaBoost-Klassifikator
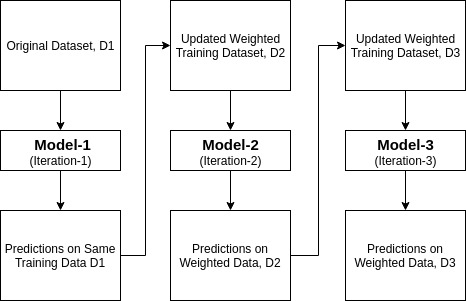
Ada-Boost oder Adaptive Boosting ist einer der 1996 von Yoav Freund und Robert Schapire vorgeschlagenen Ensemble-Boosting-Klassifikatoren. Es kombiniert mehrere Klassifikatoren, um die Genauigkeit der Klassifikatoren zu erhöhen. AdaBoost ist eine iterative Ensemble-Methode. AdaBoost Classifier erstellt einen starken Klassifikator, indem mehrere schlecht funktionierende Klassifikatoren kombiniert werden, sodass Sie einen hochgenauen starken Klassifikator erhalten. Das Grundkonzept von Adaboost besteht darin, die Gewichte von Klassifikatoren festzulegen und die Datenstichprobe in jeder Iteration so zu trainieren, dass genaue Vorhersagen ungewöhnlicher Beobachtungen sichergestellt werden. Jeder maschinelle Lernalgorithmus kann als Basisklassifikator verwendet werden, wenn er Gewichte für den Trainingssatz akzeptiert. Adaboost sollte zwei Bedingungen erfüllen:
- Der Klassifikator sollte interaktiv an verschiedenen interaktiven Trainingsbeispielen trainiert werden.
- In jeder Iteration wird versucht, eine hervorragende Anpassung für diese Beispiele bereitzustellen, indem der Trainingsfehler minimiert wird.
Wie funktioniert der AdaBoost-Algorithmus?
Es funktioniert in den folgenden Schritten:
- Zunächst wählt Adaboost eine Trainingsteilmenge zufällig aus.
- Es trainiert iterativ das maschinelle Lernmodell von AdaBoost, indem es den Trainingssatz basierend auf der genauen Vorhersage des letzten Trainings auswählt.
- Es weist falsch klassifizierten Beobachtungen das höhere Gewicht zu, so dass diese Beobachtungen in der nächsten Iteration die hohe Wahrscheinlichkeit für die Klassifizierung erhalten.
- Außerdem wird dem trainierten Klassifikator in jeder Iteration das Gewicht entsprechend der Genauigkeit des Klassifikators zugewiesen. Der genauere Klassifikator erhält ein hohes Gewicht.
- Dieser Prozess iteriert, bis die vollständigen Trainingsdaten fehlerfrei passen oder bis die angegebene maximale Anzahl von Schätzern erreicht ist.
- Führen Sie zum Klassifizieren eine „Abstimmung“ für alle von Ihnen erstellten Lernalgorithmen durch.
Modell in Python erstellen
Erforderliche Bibliotheken importieren
Laden wir zuerst die erforderlichen Bibliotheken.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsDatensatz laden
Im Modell des Gebäudeteils können Sie den IRIS-Datensatz verwenden, der ein sehr bekanntes Klassifizierungsproblem mit mehreren Klassen darstellt. Dieser Datensatz umfasst 4 Merkmale (Kelchblattlänge, Kelchblattbreite, Blütenblattlänge, Blütenblattbreite) und ein Ziel (die Art der Blume). Diese Daten haben drei Arten von Blumenklassen: Setosa, Versicolour und Virginica. Der Datensatz ist in der scikit-learn-Bibliothek verfügbar, oder Sie können ihn auch von der UCI Machine Learning Library herunterladen.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit-Datensatz
Um die Modellleistung zu verstehen, ist die Aufteilung des Datensatzes in einen Trainingssatz und einen Testsatz eine gute Strategie.
Teilen wir den Datensatz mit der Funktion train_test_split() . sie müssen 3 Parameter features , target und test_set size übergeben.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testErstellen des AdaBoost-Modells
Erstellen wir das AdaBoost-Modell mit Scikit-learn. AdaBoost verwendet Decision Tree Classifier als Standardklassifikator.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“ Die wichtigsten Parameter sind base_estimator, n_estimators und learning_rate.“ (Adaboost Klassifikator, Chris Albon)
- base_estimator: Es ist ein schwacher Lerner, der zum Trainieren des Modells verwendet wird. Es verwendet DecisionTreeClassifier als Standard für schwache Lernende zu Schulungszwecken. Sie können auch verschiedene Algorithmen für maschinelles Lernen angeben.
- n_estimators: Anzahl der schwachen Lernenden, die iterativ trainiert werden sollen.
- learning_rate: Es trägt zur Gewichtung schwacher Lernender bei. Es verwendet 1 als Standardwert.
Modell auswerten
Lassen Sie uns abschätzen, wie genau der Klassifikator oder das Modell die Art der Sorten vorhersagen kann.
Die Genauigkeit kann durch den Vergleich der tatsächlichen Testsatzwerte und der vorhergesagten Werte berechnet werden.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Nun, Sie haben eine Genauigkeit von 88,88%, die als gute Genauigkeit angesehen wird.
Zur weiteren Auswertung können Sie auch ein Modell mit verschiedenen Basisschätzern erstellen.
Verwendung verschiedener Basiswerte
Ich habe SVC als Basisschätzer verwendet. Sie können jeden ML-Lernenden als Basisschätzer verwenden, wenn er das Probengewicht akzeptiert, z. B. Entscheidungsbaum, Support-Vektor-Klassifikator.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Nun, Sie haben eine Klassifizierungsrate von 95,55%, die als gute Genauigkeit angesehen wird.
In diesem Fall erhält der SVC-Basisschätzer eine bessere Genauigkeit als der Entscheidungsbaumbasisschätzer.
Pros
AdaBoost ist einfach zu implementieren. Es korrigiert iterativ die Fehler des schwachen Klassifikators und verbessert die Genauigkeit, indem schwache Lernende kombiniert werden. Mit AdaBoost können Sie viele Basisklassifikatoren verwenden. AdaBoost ist nicht anfällig für Überanpassung. Dies kann über Experimentergebnisse herausgefunden werden, aber es gibt keinen konkreten Grund.
AdaBoost reagiert empfindlich auf Lärmdaten. Es ist stark von Ausreißern betroffen, da es versucht, jeden Punkt perfekt anzupassen. AdaBoost ist langsamer als XGBoost.
Fazit
Herzlichen Glückwunsch, Sie haben es bis zum Ende dieses Tutorials geschafft!
In diesem Tutorial haben Sie die Ensemble Machine Learning-Ansätze, den AdaBoost-Algorithmus, die Funktionsweise, den Modellaufbau und die Auswertung mit dem Python Scikit-Learn-Paket kennengelernt. Auch diskutiert seine Vor- und Nachteile.