En los últimos años, los algoritmos boosting han ganado una gran popularidad en las competiciones de ciencia de datos o aprendizaje automático. La mayoría de los ganadores de estas competiciones utilizan algoritmos de refuerzo para lograr una alta precisión. Estos concursos de ciencia de datos proporcionan la plataforma global para aprender, explorar y proporcionar soluciones para diversos problemas empresariales y gubernamentales. Los algoritmos de refuerzo combinan múltiples modelos de baja precisión(o débiles) para crear modelos de alta precisión(o fuertes). Se puede utilizar en varios dominios, como crédito, seguros, marketing y ventas. Los algoritmos de refuerzo como AdaBoost, Gradient Boost y XGBoost son algoritmos de aprendizaje automático ampliamente utilizados para ganar las competiciones de ciencia de datos. En este tutorial, vamos a aprender el AdaBoost conjunto de impulsar algoritmo, y los siguientes temas serán cubiertos:
- Conjunto Enfoque de Aprendizaje automático
- Embolsado
- Aumentar
- apilamiento
- Clasificador AdaBoost
- ¿Cómo funciona el algoritmo AdaBoost trabajo?
- Modelo de construcción en Python
- Pros y contras
- Conclusión
Enfoque de aprendizaje automático de Ensemble
Un ensemble es un modelo compuesto, combina una serie de clasificadores de bajo rendimiento con el objetivo de crear un clasificador mejorado. Aquí, se devuelve el voto clasificador individual y la etiqueta de predicción final que realiza la votación mayoritaria. Los conjuntos ofrecen más precisión que el clasificador individual o básico. Los métodos ensemble se pueden paralelizar asignando a cada alumno base a diferentes máquinas. Por último, puede decirse que los métodos de aprendizaje conjuntos son meta-algoritmos que combinan varios métodos de aprendizaje automático en un único modelo predictivo para aumentar el rendimiento. Los métodos de ensamble pueden disminuir la varianza utilizando un enfoque de ensacado, sesgo utilizando un enfoque de refuerzo o mejorar las predicciones utilizando un enfoque de apilamiento.
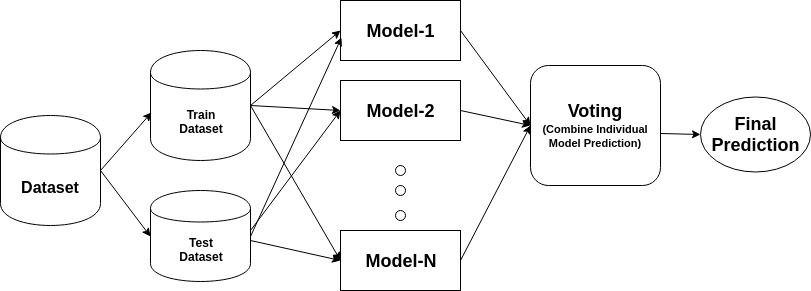
-
Ensacado significa agregación de bootstrap. Combina varios alumnos para reducir la variación de las estimaciones. Por ejemplo, el árbol de decisiones de trenes de bosque aleatorio M, puede entrenar M árboles diferentes en diferentes subconjuntos aleatorios de los datos y realizar votaciones para la predicción final. Los métodos de ensacado de conjuntos son Bosques Aleatorios y Árboles Adicionales.
-
Los algoritmos de refuerzo son un conjunto del clasificador de baja precisión para crear un clasificador de alta precisión. El clasificador de baja precisión (o clasificador débil) ofrece la precisión mejor que el lanzamiento de una moneda. El clasificador de alta precisión (o clasificador fuerte) ofrece una tasa de error cercana a 0. El algoritmo de impulso puede rastrear el modelo que falló la predicción precisa. Los algoritmos de refuerzo se ven menos afectados por el problema de sobreajuste. Los siguientes tres algoritmos han ganado una gran popularidad en las competiciones de ciencia de datos.
- AdaBoost (Potenciador adaptativo)
- Potenciador de árbol degradado
- XGBoost
-
El apilamiento (o generalización apilada) es una técnica de aprendizaje en conjunto que combina múltiples predicciones de modelos de clasificación base en un nuevo conjunto de datos. Estos nuevos datos se tratan como datos de entrada para otro clasificador. Este clasificador se empleó para resolver este problema. El apilamiento se conoce a menudo como mezcla.
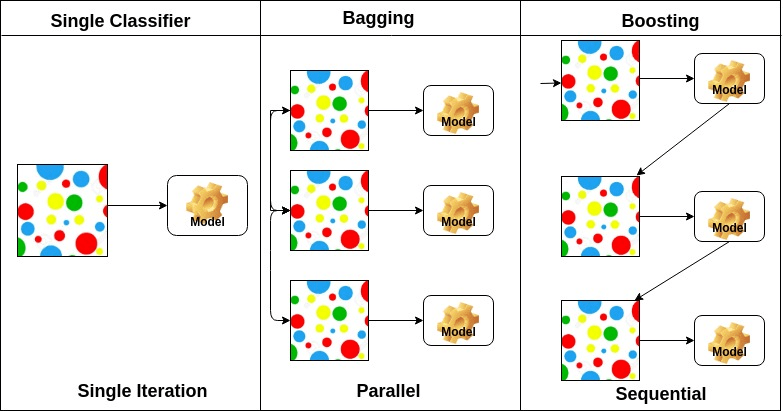
Sobre la base de la disposición de los alumnos de base, los métodos de conjunto se pueden dividir en dos grupos: En los métodos de conjunto paralelo, los alumnos de base se generan en paralelo, por ejemplo. Bosque aleatorio. En los métodos conjuntos secuenciales, los alumnos base se generan secuencialmente, por ejemplo, AdaBoost.
En función del tipo de alumnos base, los métodos conjuntos se pueden dividir en dos grupos: el método de conjunto homogéneo utiliza el mismo tipo de alumno base en cada iteración. el método de conjunto heterogéneo utiliza el tipo diferente de alumno base en cada iteración.
Clasificador AdaBoost
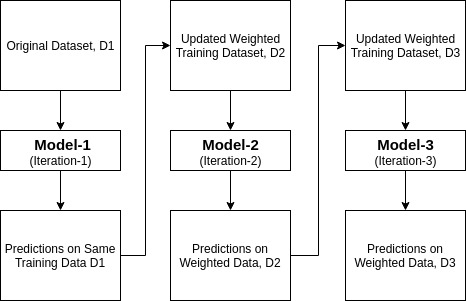
Ada-boost o Boosting Adaptativo es uno de los clasificadores de ensemble boost propuestos por Yoav Freund y Robert Schapire en 1996. Combina múltiples clasificadores para aumentar la precisión de los clasificadores. AdaBoost es un método de conjunto iterativo. El clasificador AdaBoost construye un clasificador fuerte combinando múltiples clasificadores de bajo rendimiento para que obtenga un clasificador fuerte de alta precisión. El concepto básico detrás de Adaboost es establecer los pesos de los clasificadores y entrenar la muestra de datos en cada iteración de modo que garantice las predicciones precisas de observaciones inusuales. Cualquier algoritmo de aprendizaje automático se puede usar como clasificador de base si acepta pesas en el conjunto de entrenamiento. Adaboost debe cumplir dos condiciones:
- El clasificador debe ser entrenado interactivamente en varios ejemplos de entrenamiento pesado.
- En cada iteración, intenta proporcionar un ajuste excelente para estos ejemplos minimizando los errores de entrenamiento.
¿Cómo funciona el algoritmo AdaBoost?
Funciona en los siguientes pasos:
- Inicialmente, Adaboost selecciona aleatoriamente un subconjunto de entrenamiento.
- Entrena iterativamente el modelo de aprendizaje automático AdaBoost seleccionando el conjunto de entrenamiento en función de la predicción precisa del último entrenamiento.
- Asigna el mayor peso a las observaciones clasificadas incorrectamente para que en la siguiente iteración estas observaciones obtengan la alta probabilidad de clasificación.
- Además, asigna el peso al clasificador entrenado en cada iteración de acuerdo con la precisión del clasificador. El clasificador más preciso obtendrá un alto peso.
- Este proceso se itera hasta que los datos de entrenamiento completos se ajusten sin ningún error o hasta que se alcance el número máximo de estimadores especificado.
- Para clasificar, realice un «voto» en todos los algoritmos de aprendizaje que creó.
Crear modelo en Python
Importar bibliotecas requeridas
Primero carguemos las bibliotecas requeridas.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsCargar el conjunto de datos
En el modelo de la parte de construcción, puede usar el conjunto de datos IRIS, que es un problema de clasificación multiclase muy famoso. Este conjunto de datos comprende 4 entidades (longitud de sépalo, ancho de sépalo, longitud de pétalo, ancho de pétalo) y un objetivo (el tipo de flor). Estos datos tienen tres tipos de clases de flores: Setosa, Versicolour y Virginica. El conjunto de datos está disponible en la biblioteca scikit-learn, o también puede descargarlo de la Biblioteca de Aprendizaje automático de UCI.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetDividir el conjunto de datos
Para comprender el rendimiento del modelo, dividir el conjunto de datos en un conjunto de entrenamiento y un conjunto de pruebas es una buena estrategia.
Dividamos el conjunto de datos usando la función train_test_split (). debe pasar 3 parámetros, características, destino y tamaño del conjunto de pruebas.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testConstruyendo el Modelo AdaBoost
Vamos a crear el Modelo AdaBoost usando Scikit-learn. AdaBoost utiliza el Clasificador de Árbol de Decisiones como Clasificador predeterminado.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)«Los parámetros más importantes son base_estimator, n_estimators, y learning_rate.»(Clasificador Adaboost, Chris Albon)
- base_estimator: Es un aprendiz débil usado para entrenar el modelo. Utiliza DecisionTreeClassifier como aprendiz débil predeterminado para fines de capacitación. También puede especificar diferentes algoritmos de aprendizaje automático.
- n_estimadores: Número de aprendices débiles a entrenar iterativamente.
- tasa de aprendizaje: Contribuye a los pesos de los estudiantes débiles. Utiliza 1 como valor predeterminado.
Evalúe el modelo
Estimemos con qué precisión el clasificador o modelo puede predecir el tipo de cultivares.La precisión
se puede calcular comparando los valores reales del conjunto de pruebas y los valores previstos.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Bueno, tienes una precisión del 88,88%, considerada como buena precisión.
Para una evaluación adicional, también puede crear un modelo utilizando diferentes estimadores de base.
Usando diferentes Estudiantes Base
He utilizado SVC como estimador de base. Puede usar cualquier alumno de ML como estimador de base si acepta el peso de la muestra, como Árbol de decisiones, Clasificador Vectorial de soporte.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Bueno, tienes una tasa de clasificación del 95,55%, considerada como buena precisión.
En este caso, el Estimador de Base de SVC está obteniendo una mejor precisión que el Estimador de Base de árbol de Decisión.
Pros
AdaBoost es fácil de implementar. Corrige iterativamente los errores del clasificador débil y mejora la precisión al combinar aprendices débiles. Puede utilizar muchos clasificadores de base con AdaBoost. AdaBoost no es propenso a montar en exceso. Esto se puede averiguar a través de los resultados del experimento, pero no hay una razón concreta disponible.
Cons
AdaBoost es sensible a los datos de ruido. Se ve muy afectado por valores atípicos porque trata de encajar perfectamente en cada punto. AdaBoost es más lento en comparación con XGBoost.
Conclusión
¡Felicitaciones, has llegado al final de este tutorial!
En este tutorial, ha aprendido los Enfoques de Aprendizaje Automático de Ensemble, el algoritmo AdaBoost, su funcionamiento, la construcción de modelos y la evaluación utilizando el paquete Scikit-learn de Python. También, discutió sus pros y contras.