viime vuosina tehostetut algoritmit saavuttivat valtavan suosion datatieteissä tai koneoppimiskilpailuissa. Suurin osa näiden kilpailujen voittajista käyttää tehostusalgoritmeja korkean tarkkuuden saavuttamiseksi. Nämä Data science-kilpailut tarjoavat globaalin Alustan oppimiseen, tutkimiseen ja ratkaisujen tarjoamiseen erilaisiin liike-elämän ja hallinnon ongelmiin. Lisäämällä algoritmeja yhdistää useita alhaisen tarkkuuden (tai heikko) malleja luoda korkean tarkkuuden (tai vahva) malleja. Sitä voidaan käyttää eri aloilla, kuten luotto, vakuutus, markkinointi, ja myynti. Lisäämällä algoritmeja, kuten AdaBoost, Gradient Boost, ja XGBoost ovat laajalti käytetty koneoppimisen algoritmi voittaa data science kilpailuja. Tässä opetusohjelma, aiot oppia AdaBoost ensemble lisäämällä algoritmi, ja seuraavat aiheet käsitellään:
- Ensemble koneoppimisen lähestymistapa
- Pussittaminen
- tehostaminen
- pinoaminen
- AdaBoost-luokittelija
- miten AdaBoost-algoritmi toimii?
- Building Model in Python
- plussat ja miinukset
- Conclusion
Ensemble Machine Learning Approach
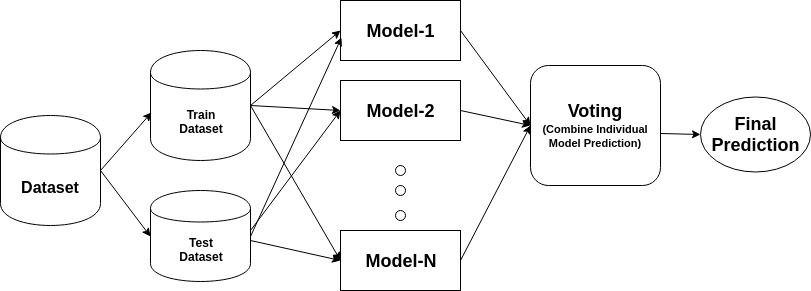
an ensemble on komposiittimalli, joka yhdistää joukon heikosti suoriutuvia luokittajia tavoitteenaan luoda parempi luokittaja. Täällä, yksittäisten luokittelija äänestää ja lopullinen ennustus etiketti palasi, joka suorittaa enemmistöäänestys. Asukokonaisuudet tarjoavat enemmän tarkkuutta kuin yksittäiset tai base luokittelija. Ensemblen menetelmiä voidaan paralleloida jakamalla jokainen perusoppija eri koneisiin. Lopuksi voidaan sanoa Ensemble-oppimismenetelmien olevan meta-algoritmeja, jotka yhdistävät useita koneoppimismenetelmiä yhdeksi ennakoivaksi malliksi suorituskyvyn lisäämiseksi. Ensemble menetelmät voivat vähentää varianssi käyttäen pussitus lähestymistapa, bias käyttäen tehostamalla lähestymistapa, tai parantaa ennusteita käyttäen pinoaminen lähestymistapa.
-
pussitus tarkoittaa bootstrap aggregaatiota. Se yhdistää useita oppijoita siten, että estimaattien vaihtelu vähenee. Esimerkiksi random forest kouluttaa M Decision Tree, voit kouluttaa M eri puita eri satunnaisten osajoukkojen tietojen ja suorittaa äänestyksen lopullinen ennustaminen. Pussituskokonaisuuksien menetelmiä ovat Satunnainen metsä ja ylimääräiset puut.
-
lisäämällä algoritmit ovat joukko Alhainen tarkka luokittelija luoda erittäin tarkka luokittelija. Alhainen tarkkuus luokittelija (tai heikko luokittelija) tarjoaa tarkkuuden parempi kuin heitto kolikon. Erittäin tarkka luokittelija (tai vahva luokittelija) tarjoavat virhetaso lähellä 0. Lisäämällä algoritmi voi seurata malli, joka epäonnistui tarkka ennustus. Algoritmien tehostamiseen liikakäyttöongelma vaikuttaa vähemmän. Seuraavat kolme algoritmia ovat saavuttaneet valtavan suosion datatieteiden kilpailuissa.
- AdaBoost (Adaptiivinen tehostaja)
- Gradienttipuun tehostaja
- XGBoost
-
pinoaminen (tai stacked generalization) on kokonaisuus-oppimistekniikka, joka yhdistää useita perusluokitusmallien ennusteita uudeksi tietokokonaisuudeksi. Näitä uusia tietoja käsitellään toisen luokittajan syöttötietoina. Tämä luokittelija käytetään ratkaisemaan tämän ongelman. Pinoamista kutsutaan usein sekoittamiseksi.
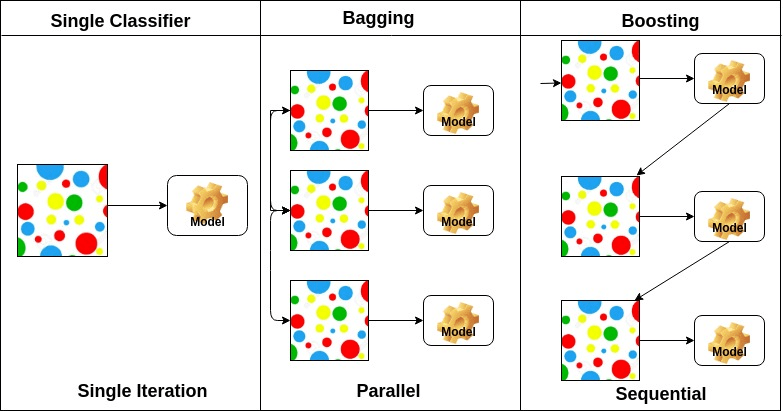
perusoppijoiden järjestelyn perusteella ensemble-menetelmät voidaan jakaa kahteen ryhmään: rinnakkaisissa ensemble-menetelmissä syntyy rinnakkain esimerkiksi perusoppijoita. Satunnaista Metsää. Sekventiaalisissa ensemble-menetelmissä perusoppijat syntyvät peräkkäin esimerkiksi AdaBoost.
perusoppijoiden tyypin perusteella ensemble-menetelmät voidaan jakaa kahteen ryhmään: homogeeninen ensemble-menetelmä käyttää jokaisessa iteraatiossa samantyyppistä perusoppijaa. heterogeeninen ensemble-metodi käyttää kussakin iteraatiossa erityyppistä perusoppijaa.
AdaBoost Classifier
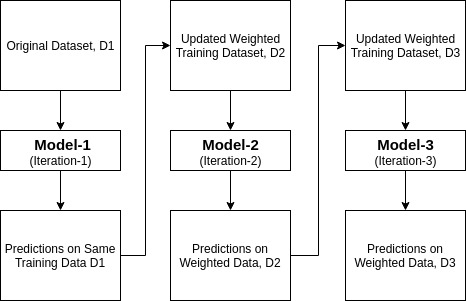
Ada-boost tai Adaptive Boosting on Yoav Freundin ja Robert Schapiren vuonna 1996 ehdottama ensemble boosting classifier. Se yhdistää useita luokittajia luokittajien tarkkuuden lisäämiseksi. AdaBoost on iteratiivinen ensemble-menetelmä. AdaBoost classifier rakentaa vahvan luokittajan yhdistämällä useita huonosti toimivia luokittajia niin, että saat korkean tarkkuuden vahva luokittaja. Adaboostin perusajatuksena on asettaa luokittajien painot ja kouluttaa datanäyte kussakin iteraatiossa siten, että se takaa epätavallisten havaintojen tarkat ennustukset. Mitä tahansa koneoppimisen algoritmia voidaan käyttää perusluokituksena, jos se hyväksyy painot harjoitussarjaan. Adaboost täyttää kaksi ehtoa:
- luokittajaa tulisi kouluttaa vuorovaikutteisesti erilaisiin punnittuihin harjoitusesimerkeihin.
- jokaisessa iteraatiossa se pyrkii tarjoamaan erinomaisen istuvuuden näihin esimerkkeihin minimoimalla harjoitusvirheen.
miten AdaBoost-algoritmi toimii?
se toimii seuraavissa vaiheissa:
- aluksi Adaboost valitsee koulutuksen osajoukon satunnaisesti.
- se harjoittelee iteratiivisesti AdaBoost-koneoppimismallia valitsemalla harjoitussarjan viimeisen harjoituksen tarkan ennustuksen perusteella.
- se antaa suuremman painoarvon väärin luokitelluille havainnoille niin, että seuraavassa iteraatiossa nämä havainnot saavat suuren todennäköisyyden luokitukseen.
- se myös määrää koulutetulle luokittajalle painon jokaisessa iteraatiossa luokittajan tarkkuuden mukaan. Tarkempi luokittelija saa suuren painon.
- tätä prosessia toistetaan, kunnes täydelliset harjoitustiedot sopivat virheettömästi tai kunnes saavutetaan määritetty estimaattorien enimmäismäärä.
- luokitellaksesi, suorita ”ääni” kaikille rakentamillesi oppimisalgoritmeille.
Rakentamismalli Pythonissa
tuo tarvittavat kirjastot
ladataan ensin tarvittavat kirjastot.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsLatausaineisto
rakennuksen osassa voi käyttää IRIS-aineistoa, joka on hyvin kuuluisa moniluokkaluokitusongelma. Tämä aineisto sisältää 4 ominaisuutta (sepal pituus, sepal leveys, terälehti pituus, terälehti leveys) ja tavoite (tyyppi Kukka). Tässä aineistossa on kolmenlaisia kukkaluokkia: Setosa, Versicolour ja Virginica. Aineisto on saatavilla scikit-learn Libraryssa tai voit ladata sen myös UCI Machine Learning Librarystä.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetJaa tietokokonaisuus
mallin suorituskyvyn ymmärtämiseksi tietokokonaisuuden jakaminen koulutus-ja koesarjaan on hyvä strategia.
jaetaan aineisto funktion train_test_split () avulla. sinun täytyy siirtää 3 parametrit ominaisuuksia, tavoite, ja test_set koko.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testrakennetaan AdaBoost-malli
luodaan AdaBoost-malli käyttäen Scikit-oppia. AdaBoost käyttää Päätöspuuluokitinta oletusluokituksena.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)”tärkeimmät parametrit ovat base_estimator, n_estimators ja learning_rate.”(Adaboost Classifier, Chris Albon)
- base_estimator: se on heikko oppija käytetään kouluttaa malli. Se käyttää DecisionTreeClassifier-Luokitusyksikköä heikkona oppijana koulutustarkoituksiin. Voit myös määrittää erilaisia koneoppimisalgoritmeja.
- n_estimators: iteratiivisesti koulutettavien heikkojen oppijoiden määrä.
- learning_rate: se vaikuttaa heikkojen oppijoiden painoihin. Se käyttää 1: tä oletusarvona.
Evaluate Model
Let ’ s estimate, how preparate what the classifier or model can predict the type of culties.
tarkkuus voidaan laskea vertaamalla todellisia testijoukon arvoja ja ennustettuja arvoja.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888tarkkuutesi on 88,88%, jota pidetään hyvänä tarkkuutena.
lisäarviointia varten voidaan myös luoda malli käyttäen erilaisia Perusestimaattoreita.
käyttäen erilaisia Perusoppijoita
olen käyttänyt SVC: tä perusestimaattorina. Voit käyttää mitä tahansa ML-oppijaa perusestimaattorina, jos se hyväksyy näytteen painon, kuten päätöksen Puu, Tukivektorin luokittelija.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556arvosanasi on 95,55%, jota pidetään hyvänä tarkkuutena.
tässä tapauksessa SVC-Base-estimaattori saa paremman tarkkuuden kuin Päätöspuun Base-estimaattori.
plussat
AdaBoost on helppo toteuttaa. Se korjaa iteratiivisesti heikon luokittajan virheitä ja parantaa tarkkuutta yhdistämällä heikkoja oppijoita. Voit käyttää monia base luokittelijoita AdaBoost. AdaBoost ei ole altis ylilyönneille. Tämä selviää kokeilutulosten kautta, mutta konkreettista syytä ei ole saatavilla.
Cons
AdaBoost on herkkä melutiedoille. Poikkeamat vaikuttavat siihen suuresti, koska se pyrkii sopimaan jokaiseen pisteeseen täydellisesti. AdaBoost on hitaampi kuin XGBoost.
johtopäätös
Onneksi olkoon, olet selvinnyt tämän opetusohjelman loppuun asti!
tässä opetusohjelmassa olet oppinut Ensemble koneoppimisen lähestymistavat, AdaBoost-algoritmin, it ’ s workingin, mallin rakentamisen ja arvioinnin Python Scikit-learn-paketilla. Keskusteltiin myös sen eduista ja haitoista.