under de senaste åren, öka algoritmer vunnit massiv popularitet i datavetenskap eller maskininlärning tävlingar. De flesta av vinnarna av dessa tävlingar använder boostande algoritmer för att uppnå hög noggrannhet. Dessa datavetenskapstävlingar ger den globala plattformen för lärande, utforska och tillhandahålla lösningar för olika affärs-och regeringsproblem. Öka algoritmer kombinera flera låg noggrannhet (eller svaga) modeller för att skapa en hög noggrannhet(eller starka) modeller. Det kan användas i olika domäner som kredit, försäkring, marknadsföring och försäljning. Boosting algoritmer som AdaBoost, Gradient Boosting och XGBoost används ofta maskininlärningsalgoritm för att vinna datavetenskapstävlingarna. I den här handledningen kommer du att lära dig AdaBoost ensemble boosting algorithm, och följande ämnen kommer att behandlas:
- Ensemble maskininlärning tillvägagångssätt
- uppsamlare
- öka
- stapling
- AdaBoost-klassificerare
- hur fungerar AdaBoost-algoritmen?
- byggnadsmodell i Python
- fördelar och nackdelar
- slutsats
Ensemble Machine Learning Approach
en ensemble är en sammansatt modell, kombinerar en serie lågpresterande klassificerare med målet att skapa en förbättrad klassificerare. Här återvände individuell klassificeringsröstning och slutlig förutsägelsesetikett som utför majoritetsröstning. Ensembler erbjuder mer noggrannhet än individ eller bas klassificerare. Ensemblemetoder kan parallelliseras genom att allokera varje baslärare till olika olika maskiner. Slutligen kan du säga att Ensembleinlärningsmetoder är metaalgoritmer som kombinerar flera maskininlärningsmetoder i en enda prediktiv modell för att öka prestanda. Ensemblemetoder kan minska variansen med hjälp av bagging-tillvägagångssätt, bias med hjälp av en boosting-metod eller förbättra förutsägelser med hjälp av staplingsmetod.
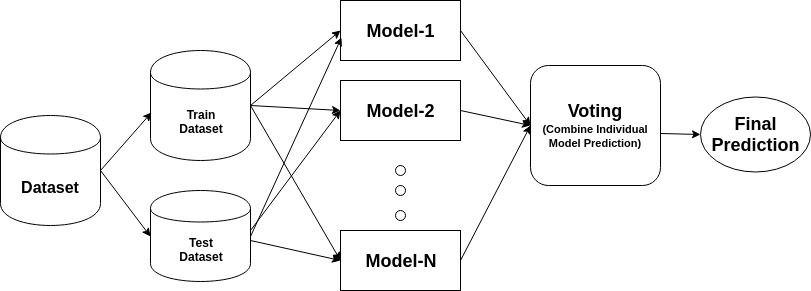
-
Bagging står för bootstrap aggregation. Den kombinerar flera elever på ett sätt att minska variansen i uppskattningar. Till exempel, slumpmässiga skogståg m beslutsträd, du kan träna M olika träd på olika slumpmässiga delmängder av data och utföra röstning för slutlig förutsägelse. Uppsamlare ensembler metoder är slumpmässiga skog och Extra träd.
-
öka algoritmer är en uppsättning av låg exakt klassificerare för att skapa en mycket exakt klassificerare. Låg noggrannhetsklassificerare (eller svag klassificerare) erbjuder noggrannheten bättre än att vända ett mynt. Mycket exakt klassificerare (eller stark klassificerare) erbjuder felfrekvens nära 0. Boosting algoritm kan spåra modellen som misslyckades med den exakta förutsägelsen. Boosting algoritmer påverkas mindre av överfittningsproblemet. Följande tre algoritmer har vunnit massiv popularitet i datavetenskapstävlingar.
- AdaBoost (adaptiv Boosting)
- Gradient träd Boosting
- XGBoost
-
stapling (eller staplad generalisering) är en ensemble inlärningsteknik som kombinerar flera bas klassificeringsmodeller förutsägelser i en ny datamängd. Dessa nya data behandlas som indata för en annan klassificerare. Denna klassificerare används för att lösa detta problem. Stapling kallas ofta blandning.
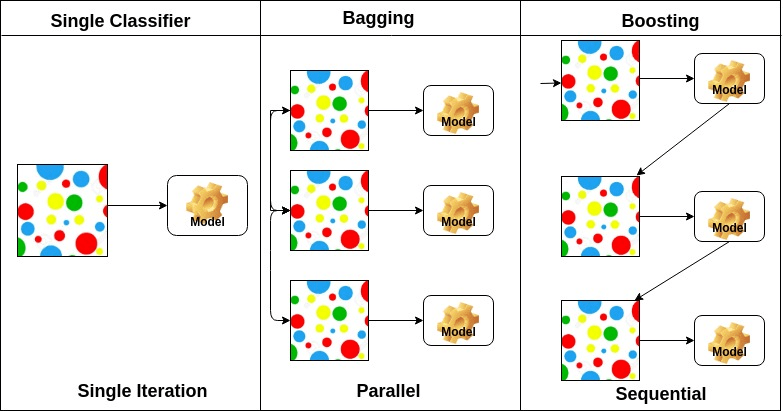
på grundval av arrangemanget av baselever kan ensemblemetoder delas in i två grupper: i parallella ensemblemetoder genereras baselever parallellt till exempel. Slumpmässig Skog. I sekventiella ensemblemetoder genereras baselever sekventiellt till exempel AdaBoost.
på grundval av typen av baselever kan ensemblemetoder delas in i två grupper: homogen ensemblemetod använder samma typ av baslärare i varje iteration. heterogen ensemblemetod använder olika typer av baslärare i varje iteration.
AdaBoost Classifier
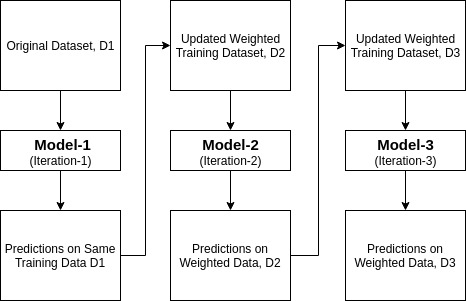
Ada-boost eller adaptiv Boosting är en av ensemble boosting classifier som föreslagits av Yoav Freund och Robert Schapire 1996. Den kombinerar flera klassificerare för att öka noggrannheten hos klassificerare. AdaBoost är en iterativ ensemblemetod. AdaBoost classifier bygger en stark klassificerare genom att kombinera flera dåligt presterande klassificerare så att du får hög noggrannhet stark klassificerare. Det grundläggande konceptet bakom Adaboost är att ställa in klassificeringsvikterna och träna dataprovet i varje iteration så att det säkerställer exakta förutsägelser av ovanliga observationer. Varje maskininlärningsalgoritm kan användas som basklassificerare om den accepterar vikter på träningsuppsättningen. Adaboost ska uppfylla två villkor:
- klassificeraren bör utbildas interaktivt på olika vägda träningsexempel.
- i varje iteration försöker den ge en utmärkt passform för dessa exempel genom att minimera träningsfel.
hur fungerar AdaBoost-algoritmen?
det fungerar i följande steg:
- inledningsvis väljer Adaboost en träningsdelmängd slumpmässigt.
- det tränar iterativt AdaBoost-maskininlärningsmodellen genom att välja träningsuppsättningen baserat på den exakta förutsägelsen för den senaste träningen.
- den tilldelar den högre vikten till felaktiga klassificerade observationer så att i nästa iteration kommer dessa observationer att få stor sannolikhet för klassificering.
- det tilldelar också vikten till den utbildade klassificeraren i varje iteration enligt klassificerarens noggrannhet. Den mer exakta klassificeraren kommer att få hög vikt.
- denna process upprepas tills hela träningsdata passar utan något fel eller tills det uppnås till det angivna maximala antalet estimatorer.
- för att klassificera, utför en” röst ” över alla inlärningsalgoritmer du byggt.
Byggmodell i Python
importera obligatoriska Bibliotek
Låt oss först ladda de nödvändiga biblioteken.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsladdar Dataset
i modellen byggnadsdelen kan du använda IRIS dataset, vilket är ett mycket känt klassificeringsproblem i flera klasser. Denna dataset består av 4 funktioner (sepal längd, sepal bredd, kronblad längd, kronblad bredd) och ett mål (den typ av blomma). Dessa data har tre typer av blomklasser: Setosa, Versicolour och Virginica. Datauppsättningen finns i scikit-learn-biblioteket, eller så kan du också ladda ner den från UCI Machine Learning Library.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit dataset
för att förstå modellprestanda är det en bra strategi att dela datasetet i en träningsuppsättning och en testuppsättning.
Låt oss dela dataset med hjälp av funktionen train_test_split (). du måste passera 3 parametrar funktioner, mål och test_set storlek.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testbygga AdaBoost-modellen
Låt oss skapa AdaBoost-modellen med Scikit-learn. AdaBoost använder Decision Tree Classifier som Standardklassificerare.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)”de viktigaste parametrarna är base_estimator, n_estimators och learning_rate.”(Adaboost Classifier, Chris Albon)
- base_estimator: det är en svag elev som används för att träna modellen. Den använder DecisionTreeClassifier som standard svag elev för utbildning ändamål. Du kan också ange olika maskininlärningsalgoritmer.
- n_estimators: antal svaga elever att träna iterativt.
- learning_rate: det bidrar till vikterna hos svaga elever. Den använder 1 som standardvärde.
utvärdera Modell
låt oss uppskatta hur exakt klassificeraren eller modellen kan förutsäga typen av sorter.
noggrannhet kan beräknas genom att jämföra faktiska testuppsättningsvärden och förutsagda värden.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Tja, du har en noggrannhet på 88,88%, betraktad som god noggrannhet.
för vidare utvärdering kan du också skapa en modell med olika Basberäkningar.
använda olika Baselever
jag har använt SVC som basberäkare. Du kan använda vilken ML-elev som basberäkare om den accepterar provvikt som beslutsträd, Stödvektorklassificerare.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Tja, du har en klassificeringsgrad på 95,55%, betraktad som god noggrannhet.
i detta fall får SVC Base Estimator bättre noggrannhet än Decision tree Base Estimator.
fördelar
AdaBoost är lätt att implementera. Det korrigerar iterativt den svaga klassificerarens misstag och förbättrar noggrannheten genom att kombinera svaga elever. Du kan använda många bas klassificerare med AdaBoost. AdaBoost är inte benägen att överfitta. Detta kan hittas via experimentresultat, men det finns ingen konkret anledning tillgänglig.
nackdelar
AdaBoost är känslig för brusdata. Det påverkas starkt av avvikare eftersom det försöker passa varje punkt perfekt. AdaBoost är långsammare jämfört med XGBoost.
slutsats
Grattis, du har gjort det till slutet av denna handledning!
i den här handledningen har du lärt dig Ensemblemaskininlärningsmetoderna, AdaBoost-algoritmen, det fungerar, modellbyggnad och utvärdering med Python Scikit-learn-paketet. Också diskuterade dess fördelar och nackdelar.