i de senere år har boosting af algoritmer fået massiv popularitet inden for datalogi eller maskinindlæringskonkurrencer. De fleste af vinderne af disse konkurrencer bruger boostende algoritmer for at opnå høj nøjagtighed. Disse datavidenskabskonkurrencer giver den globale platform for læring, udforskning og levering af løsninger til forskellige forretnings-og regeringsproblemer. Boosting algoritmer kombinerer flere lav nøjagtighed(eller svage) modeller til at skabe en høj nøjagtighed(eller stærke) modeller. Det kan udnyttes i forskellige domæner såsom kredit, forsikring, markedsføring og salg. AdaBoost, Gradient Boosting, er meget udbredt machine learning algoritme til at vinde data science konkurrencer. I denne tutorial, du vil lære AdaBoost ensemble boosting algoritme, og følgende emner vil blive dækket:
- Ensemble Machine Learning Approach
- sække
- Boosting
- stabling
- AdaBoost-klassifikator
- Hvordan fungerer AdaBoost-algoritmen?
- bygningsmodel i Python
- fordele og ulemper
- konklusion
Ensemble Machine Learning Approach
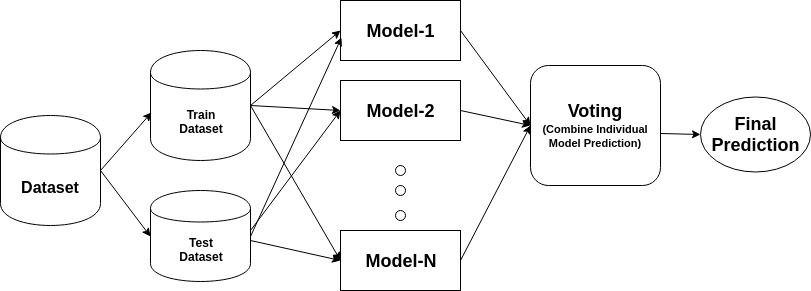
et ensemble er en sammensat model, kombinerer en række lavpræsterende klassifikatorer med det formål at skabe en forbedret klassifikator. Her returneres individuel klassificeringsstemme og endelig forudsigelsesetiket, der udfører flertalsafstemning. Ensembler tilbyder mere nøjagtighed end individuel eller basisklassifikator. Ensemble metoder kan parallelisere ved at tildele hver base elev til forskellige-forskellige maskiner. Endelig kan du sige, at Ensemblelæringsmetoder er meta-algoritmer, der kombinerer flere maskinlæringsmetoder til en enkelt forudsigelig model for at øge ydeevnen. Ensemblemetoder kan reducere variansen ved hjælp af bagging-tilgang, bias ved hjælp af en boostende tilgang eller forbedre forudsigelser ved hjælp af stablingstilgang.
-
Bagging står for bootstrap aggregation. Det kombinerer flere elever på en måde at reducere variansen af estimater. For eksempel, tilfældige skovtog M beslutningstræ, du kan træne M forskellige træer på forskellige tilfældige delmængder af dataene og udføre afstemning for endelig forudsigelse. Sække ensembler metoder er tilfældige Skov og ekstra træer.
-
Boosting algoritmer er et sæt af den lave nøjagtige klassifikator for at skabe en meget nøjagtig klassifikator. Klassifikator med lav nøjagtighed (eller svag klassifikator) giver nøjagtigheden bedre end flipping af en mønt. Meget nøjagtig klassifikator (eller stærk klassifikator) tilbyder fejlfrekvens tæt på 0. Boosting algoritme kan spore den model, der mislykkedes den nøjagtige forudsigelse. Boosting algoritmer er mindre påvirket af overmontering problemet. De følgende tre algoritmer har vundet massiv popularitet i datavidenskabskonkurrencer.
- AdaBoost (adaptiv Boosting)
- Gradient træ Boosting
-
stabling (eller stablet generalisering) er et ensemble læring teknik, der kombinerer flere base klassificering modeller forudsigelser i et nyt datasæt. Disse nye data behandles som inputdata for en anden klassifikator. Denne klassifikator anvendes til at løse dette problem. Stacking kaldes ofte blanding.
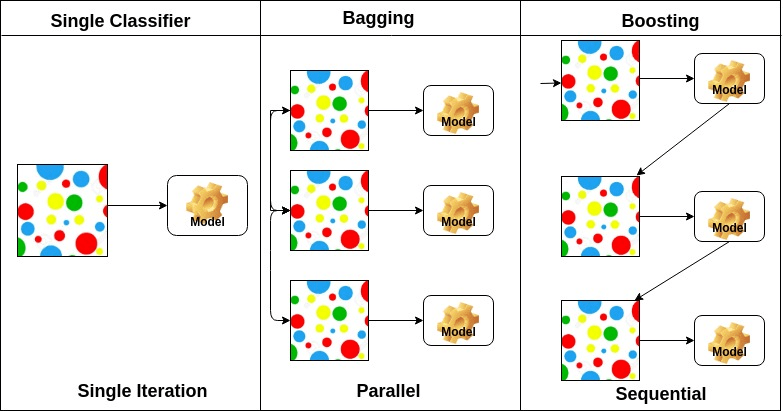
på baggrund af arrangementet af basiselever kan ensemblemetoder opdeles i to grupper: i parallelle ensemblemetoder genereres basiselever parallelt for eksempel. Tilfældig Skov. I sekventielle ensemblemetoder genereres baseelever sekventielt for eksempel AdaBoost.
på grundlag af typen af baseelever kan ensemblemetoder opdeles i to grupper: homogen ensemblemetode bruger den samme type baselærer i hver iteration. heterogen ensemblemetode bruger den forskellige type baselærer i hver iteration.
AdaBoost Classifier
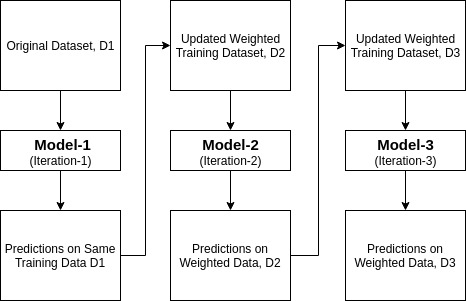
Ada-boost eller Adaptive Boosting er en af ensemble boosting classifier foreslået af Yoav Freund og Robert Schapire i 1996. Det kombinerer flere klassifikatorer for at øge nøjagtigheden af klassifikatorer. AdaBoost er en iterativ ensemble metode. AdaBoost classifier bygger en stærk klassifikator ved at kombinere flere Dårligt præsterende klassifikatorer, så du får høj nøjagtighed stærk klassifikator. Det grundlæggende koncept bag Adaboost er at indstille vægten af klassifikatorer og træne dataprøven i hver iteration, så den sikrer de nøjagtige forudsigelser af usædvanlige observationer. Enhver maskinlæringsalgoritme kan bruges som basisklassifikator, hvis den accepterer vægte på træningssættet. Adaboost skal opfylde to betingelser:
- klassifikatoren skal trænes interaktivt på forskellige vejede træningseksempler.
- i hver iteration forsøger den at give en fremragende pasform til disse eksempler ved at minimere træningsfejl.
Hvordan fungerer AdaBoost-algoritmen?
det fungerer i følgende trin:
- oprindeligt vælger Adaboost en træningsdelmængde tilfældigt.
- det træner iterativt AdaBoost machine learning-modellen ved at vælge træningssættet baseret på den nøjagtige forudsigelse af den sidste træning.
- det tildeler den højere vægt til forkerte klassificerede observationer, så disse observationer i den næste iteration får høj sandsynlighed for klassificering.
- det tildeler også vægten til den uddannede klassifikator i hver iteration i henhold til klassificeringens nøjagtighed. Den mere præcise klassifikator vil få høj vægt.
- denne proces gentages, indtil de komplette træningsdata passer uden nogen fejl, eller indtil de nås til det angivne maksimale antal estimatorer.
- for at klassificere skal du udføre en “stemme” på tværs af alle de læringsalgoritmer, du har bygget.
bygningsmodel i Python
import af nødvendige biblioteker
lad os først indlæse de nødvendige biblioteker.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsindlæser datasæt
i modellen bygningsdelen kan du bruge IRIS-datasættet, som er et meget berømt klassificeringsproblem i flere klasser. Dette datasæt består af 4 funktioner (sepal længde, sepal bredde, kronblad længde, kronblad bredde) og et mål (typen af blomst). Disse data har tre typer af blomster klasser: Setosa, versicolor og Virginica. Datasættet er tilgængeligt i scikit-learn-biblioteket, eller du kan også hente det fra UCI Machine Learning-biblioteket.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit datasæt
for at forstå modelpræstation er det en god strategi at opdele datasættet i et træningssæt og et testsæt.
lad os opdele datasæt ved hjælp af funktionen train_test_split(). du er nødt til at passere 3 parametre funktioner, mål, og test_set størrelse.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testopbygning af AdaBoost-modellen
lad os oprette AdaBoost-modellen ved hjælp af Scikit-learn. AdaBoost bruger Decision Tree Classifier som standard klassifikator.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“de vigtigste parametre er base_estimator, n_estimators og learning_rate.”(AdaBoost klassifikator, Chris Albon)
- base_estimator: det er en svag elev, der bruges til at træne modellen. Det bruger DecisionTreeClassifier som standard svag elev til træningsformål. Du kan også angive forskellige maskinlæringsalgoritmer.
- n_estimators: antal svage elever til at træne iterativt.
- learning_rate: det bidrager til vægten af svage elever. Det bruger 1 som standardværdi.
Evaluer Model
lad os estimere, hvor præcist klassifikatoren eller modellen kan forudsige typen af sorter.
nøjagtighed kan beregnes ved at sammenligne faktiske test sæt værdier og forudsagte værdier.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Nå, du har en nøjagtighed på 88,88%, betragtes som god nøjagtighed.
for yderligere evaluering kan du også oprette en model ved hjælp af forskellige Basisestimatorer.
brug af forskellige Baseelever
jeg har brugt SVC som basestimator. Du kan bruge enhver ML-elev som basisestimator, hvis den accepterer prøvevægt, såsom beslutningstræ, Supportvektorklassifikator.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Nå, du har en klassificeringsgrad på 95,55%, betragtes som god nøjagtighed.
i dette tilfælde bliver SVC Base Estimator bedre nøjagtighed end Decision tree Base Estimator.
Pros
AdaBoost er let at implementere. Det korrigerer iterativt fejlene i den svage klassifikator og forbedrer nøjagtigheden ved at kombinere svage elever. Du kan bruge mange base klassifikatorer med AdaBoost. AdaBoost er ikke tilbøjelig til overfitting. Dette kan findes via eksperimentresultater, men der er ingen konkret grund til rådighed.
ulemper
AdaBoost er følsom over for støjdata. Det er stærkt påvirket af outliers, fordi det forsøger at passe hvert punkt perfekt. AdaBoost er langsommere sammenlignet med Gboost.
konklusion
Tillykke, du har gjort det til slutningen af denne tutorial!
i denne tutorial har du lært Ensemble Machine Learning-tilgange, AdaBoost-algoritme, det fungerer, modelopbygning og evaluering ved hjælp af Python Scikit-Lær pakke. Også diskuteret sine fordele og ulemper.