az elmúlt években a növelő algoritmusok hatalmas népszerűségre tettek szert az adattudományi vagy gépi tanulási versenyeken. E versenyek nyerteseinek többsége növelő algoritmusokat használ a nagy pontosság elérése érdekében. Ezek az adattudományi versenyek biztosítják a globális platformot a különböző üzleti és kormányzati problémák tanulásához, feltárásához és megoldásához. A növelő algoritmusok több alacsony pontosságú(vagy gyenge) modellt kombinálnak, hogy nagy pontosságú(vagy erős) modelleket hozzanak létre. Ezt fel lehet használni a különböző területeken, mint a hitel, a biztosítás, a marketing és az értékesítés. Az olyan gyorsító algoritmusok, mint az AdaBoost, a Gradient Boost és az XGBoost széles körben használják a gépi tanulási algoritmust az adattudományi versenyek megnyerésére. Ebben az oktatóanyagban meg fogja tanulni az AdaBoost ensemble boosting algoritmust, és a következő témákkal foglalkozik:
- Ensemble gépi tanulási megközelítés
- zsákolás
- Boosting
- halmozás
- AdaBoost osztályozó
- hogyan működik az AdaBoost algoritmus?
- Building Model in Python
- érvek és ellenérvek
- következtetés
Ensemble Machine Learning Approach
az ensemble egy összetett modell, amely egy sor alacsony teljesítményű osztályozót egyesít azzal a céllal, hogy jobb osztályozót hozzon létre. Itt az egyéni osztályozó szavazás és a végső előrejelzési címke visszatért, amely többségi szavazást végez. Az együttesek nagyobb pontosságot kínálnak, mint az egyéni vagy az alaposztályozók. Az együttes módszerek párhuzamosíthatók azáltal, hogy az egyes alaptanulókat különböző gépekhez rendelik. Végül elmondhatjuk, hogy az együttes tanulási módszerek olyan meta-algoritmusok, amelyek több gépi tanulási módszert egyetlen prediktív modellbe egyesítenek a teljesítmény növelése érdekében. Az együttes módszerek csökkenthetik a varianciát zsákolási megközelítéssel, elfogultság növelő megközelítéssel, vagy javíthatják az előrejelzéseket egymásra rakható megközelítéssel.
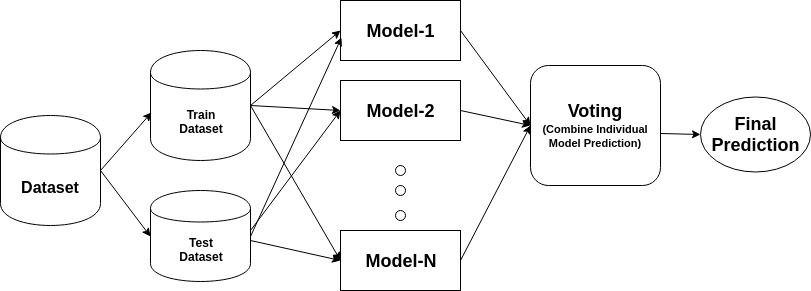
-
a zsákolás a bootstrap aggregation rövidítése. Több tanulót egyesít oly módon, hogy csökkentse a becslések varianciáját. Például random forest vonatok M döntési fa, akkor a vonat m különböző fák különböző véletlenszerű részhalmazai az adatok és a szavazás a végső előrejelzést. Zsákolás együttesek módszerek véletlenszerű erdő és Extra fák.
-
A növelő algoritmusok az alacsony pontosságú osztályozó készletei, amelyek nagyon pontos osztályozót hoznak létre. Az alacsony pontosságú osztályozó (vagy gyenge osztályozó) jobb pontosságot kínál, mint egy érme megfordítása. Nagyon pontos osztályozó (vagy erős osztályozó) ajánlat hibaarány közel 0. Fellendítése algoritmus nyomon tudja követni a modell, aki nem a pontos előrejelzést. A növelő algoritmusokat kevésbé érinti a túlillesztési probléma. A következő három algoritmus hatalmas népszerűségre tett szert az adattudományi versenyeken.
- AdaBoost (adaptív növelése)
- gradiens fa növelése
- XGBoost
-
a halmozás (vagy halmozott általánosítás) egy együttes tanulási technika, amely több alaposztályozási modell előrejelzését ötvözi egy új adathalmazba. Ezeket az új adatokat egy másik osztályozó bemeneti adataként kezeljük. Ez osztályozó alkalmazott megoldani ezt a problémát. Az egymásra rakást gyakran keverésnek nevezik.
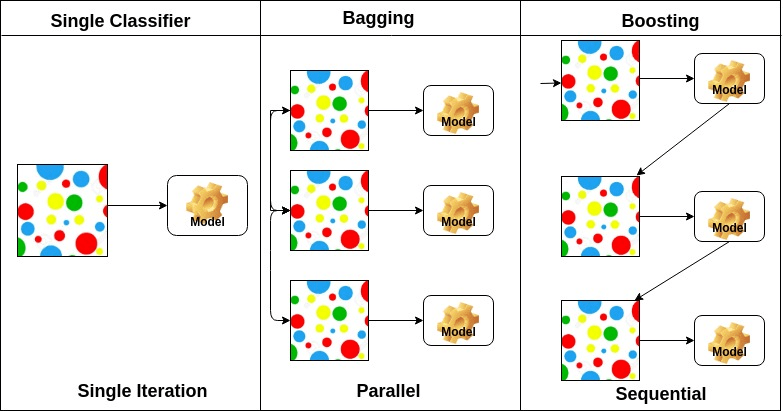
az alaptanulók elrendezése alapján, az ensemble módszerek két csoportra oszthatók: párhuzamos ensemble módszerekben, az alaptanulókat például párhuzamosan generálják. Véletlen Erdő. Szekvenciális együttes módszerekben az alaptanulókat például egymás után generálják AdaBoost.
az alaptanulók típusa alapján az együttes módszerek két csoportra oszthatók: homogén ensemble módszer ugyanazt a típusú alap tanuló minden iteráció. a heterogén együttes módszer az egyes iterációkban a különböző típusú alaptanulókat használja.
AdaBoost Classifier
Ada-boost vagy adaptív Boosting az egyik ensemble boosting osztályozó által javasolt Yoav Freund és Robert Schapire 1996-ban. Több osztályozót egyesít az osztályozók pontosságának növelése érdekében. Az AdaBoost egy iteratív együttes módszer. AdaBoost osztályozó épít egy erős osztályozó kombinálásával több rosszul teljesítő osztályozók úgy, hogy kapsz nagy pontosságú erős osztályozó. Az Adaboost alapkoncepciója az osztályozók súlyának beállítása és az adatminta betanítása minden iterációban úgy, hogy biztosítsa a szokatlan megfigyelések pontos előrejelzését. Bármely gépi tanulási algoritmus használható alaposztályozóként, ha elfogadja a súlyokat a képzési készleten. Az adaboostnak két feltételnek kell megfelelnie:
- az osztályozót interaktívan kell kiképezni különféle lemért edzési példákon.
- minden iterációban megpróbálja kiválóan illeszkedni ezekhez a példákhoz azáltal, hogy minimalizálja az edzési hibákat.
hogyan működik az AdaBoost algoritmus?
a következő lépésekben működik:
- kezdetben az Adaboost véletlenszerűen választ ki egy képzési részhalmazt.
- iteratív módon edzi az AdaBoost gépi tanulási modellt azáltal, hogy kiválasztja az edzőkészletet az utolsó edzés pontos előrejelzése alapján.
- a nagyobb súlyt a rossz Osztályozott megfigyelésekhez rendeli, így a következő iterációban ezek a megfigyelések nagy valószínűséggel lesznek osztályozva.
- ezenkívül minden iterációban hozzárendeli a súlyt a betanított osztályozóhoz az osztályozó pontossága szerint. A pontosabb osztályozó nagy súlyt kap.
- ez a folyamat addig ismétlődik, amíg a teljes képzési adatok hiba nélkül nem illeszkednek, vagy amíg el nem érik a megadott maximális becslési számot.
- az osztályozáshoz hajtson végre egy “szavazást” az összes épített tanulási algoritmuson.
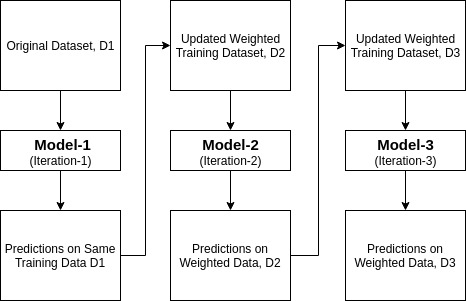
építési modell Pythonban
szükséges könyvtárak importálása
először töltsük be a szükséges könyvtárakat.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsadatkészlet betöltése
a modellben az épületrészben használhatja az IRIS adatkészletet, amely egy nagyon híres több osztályú osztályozási probléma. Ez az adatkészlet 4 jellemzőt tartalmaz (sepal hossza, sepal szélessége, szirom hossza, szirom szélessége) és egy célt (a virág típusa). Ezeknek az adatoknak háromféle virágosztálya van: setosa, Versicolour és Virginica. Az adatkészlet elérhető a scikit-learn könyvtárban, vagy letöltheti az UCI Machine Learning könyvtárból is.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetosztott adatkészlet
a modell teljesítményének megértéséhez jó stratégia az adatkészlet képzési és tesztkészletre osztása.
Osszuk meg az adatkészletet a train_test_split () függvény használatával. be kell, hogy adja át 3 paraméter jellemzői, cél, és test_set mérete.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testaz AdaBoost modell felépítése
hozzuk létre az AdaBoost modellt a Scikit-learn használatával. AdaBoost használ döntési fa osztályozó alapértelmezett osztályozó.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“a legfontosabb paraméterek a base_estimator, az n_estimators és a learning_rate.”(Adaboost osztályozó, Chris Albon)
- base_estimator: ez egy gyenge tanuló, akit a modell edzésére használnak. Használja DecisionTreeClassifier alapértelmezett gyenge tanuló képzési célra. Különböző gépi tanulási algoritmusokat is megadhat.
- n_estimators: az iteratív edzéshez szükséges gyenge tanulók száma.
- learning_rate: hozzájárul a gyenge tanulók súlyához. Alapértelmezett értékként 1-et használ.
értékelje a
modellt becsüljük meg, hogy az osztályozó vagy modell pontosan meg tudja jósolni a fajták típusát.
a pontosság kiszámítható a tényleges tesztkészletek és az előre jelzett értékek összehasonlításával.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888nos, 88,88% – os pontosságot kapott, ami jó pontosságnak tekinthető.
további értékeléshez modellt is létrehozhat különböző Alapbecslőkkel.
különböző Alaptanulók használata
az SVC-t használtam alapbecslőként. Használhatja bármilyen ML tanuló alap becslő, ha elfogadja minta súlya, mint a döntési fa, támogatás Vektor osztályozó.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556nos, 95,55% – os besorolási arányt kapott, ami jó pontosságnak tekinthető.
ebben az esetben az SVC Alapbecslő jobb pontosságot kap, mint a döntési fa Alapbecslő.
előnyök
az AdaBoost könnyen megvalósítható. Iteratív módon kijavítja a gyenge osztályozó hibáit, és javítja a pontosságot a gyenge tanulók kombinálásával. Számos alaposztályozót használhat az AdaBoost segítségével. Az AdaBoost nem hajlamos a túlzott felszerelésre. Ezt a kísérlet eredményein keresztül lehet megtudni,de nincs konkrét ok.
hátrányok
az AdaBoost érzékeny a zajadatokra. Erősen befolyásolja a kiugró értékek, mert megpróbálja tökéletesen illeszkedni az egyes pontokhoz. Az AdaBoost lassabb az Xgboosthoz képest.
következtetés
Gratulálunk, sikerült a bemutató végére jutnod!
ebben az oktatóanyagban megtanultad az Ensemble Machine Learning megközelítéseket, az AdaBoost algoritmust, a munkát, a Modellépítést és az értékelést a Python Scikit-learn csomag segítségével. Is, megvitatta annak előnyeit és hátrányait.